日本一わかりやすいLoRA学習!sd-scripts導入から学習実行まで解説!東北ずん子LoRAを作ってみよう!【Stable Diffusion】
#Dreambooth #training #東北ずん子 #LoRA学習 やり方 #sdscripts #ローラ学習 #stablediffusion #aiart #automatic1111 #python3.10.6 #WD14Tagger #LoRA #kohya #AIモデル解説 #AIモ...

日本一わかりやすいLoRA学習!sd-scripts導入から学習実行まで解説!東北ずん子LoRAを作ってみよう!【Stable Diffusion】
#Dreambooth #training #東北ずん子 #LoRA学習 やり方 #sdscripts #ローラ学習 #stablediffusion #aiart #automatic1111 #python3.10.6 #WD14Tagger #LoRA #kohya #AIモデル解説 #AIモ...
日本一わかりやすいLoRA学習!sd-scripts導入から学習実行まで解説!東北ずん子LoRAを作ってみよう!【Stable Diffusion】
#sdscripts #ローラ学習 #stablediffusion #aiart #automatic1111 #python3.10.6 #WD14Tagger #LoRA #kohya #Dreambooth #training #東北ずん子 #LoRA学習 やり方 #AIモデル解説 #AIモ...

Entrenar mi propio #lora no funciono muy bien :( #dreambooth
corre en la terminal, pero no tiene efecto dentro de #krita

Dear Mastodon, what are your favorite #DreamBooth prompts?
I watched some youtube. Tried some, but I feel everything I am trying is wildly inconsistent. I get one I like for every 16 or so images, maybe less.
(For context, all of these are generative ai, created from a training model I created in DreamBooth, inside Automatic1111. I'm finding it hard to re-create the aspects I even like about some of my favorites.)




Tried to train AI to make a few funny photos of my kiddo. The results are kind of funny but... NO

Ever wondered what it looks like to create high quality printable works of art with Stable Diffusion?
I just published my latest blog post about how I used Stable Diffusion and Dreambooth to create a "painted" portrait of my dog 🧀 Queso

In this post, we walk through my entire workflow/process for bringing Stable Diffusion to life as a high-quality framed art print. We’ll touch on making art with Dreambooth, Stable Diffusion, Outpainting, Inpainting, Upscaling, preparing for print with Photoshop, and finally printing on fine-art paper with an Epson XP-15000 printer.
#LoRA :Low-Rank Adaptation of Large Language Models
昨天速学LoRA今天就要给友友们讲了!紧张!希望没讲错!顺便把拖了很久的 #DreamBooth 一并讲了。
要讲LoRA就要先讲模型finetune。模型的finetune指的是什么呢?其实就是当你有一个现成的,很厉害的大模型(pre-trained model),你想要让它学一些新知识,或者完成一些更面向具体应用的子任务,或者只是为了适配你的数据分布时,就需要拿你的小数据去对模型进行重新训练。这个训练不能训太久,否则模型就会过拟合到你的小样本数据上。
pre-train + finetune 是机器学习非常常见的组合,在应用上有很大价值。但是最常见的一个问题就是“遗忘”。模型会在finetune过程中不断忘记之前已经记住的内容。
常见的解决方案中,一个是replay,就是也把原始知识过一遍;第二个是正则化,通过正则项控制模型参数和原始参数尽量一致,不要变太多;还有一个是Parameter isolation(参数孤立化),这个是通过独立出一个模块来做finetune,原有的模型不再更新权重。
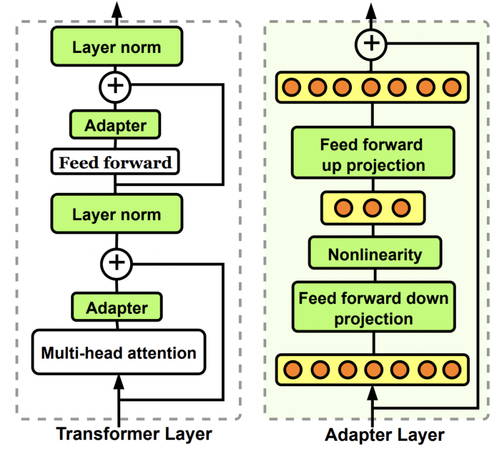
参数孤立化是最有效的一种方式,具体有好几种实现方式,例如Adaptor(P1)就是在原模型中增加一个子模块,固定原模型,只训练子模块。是不是听起来很熟悉?是的,ControlNet就是一种类似Adaptor的方法,同理还有T2I-Adapter,也是通过增加子模块来引入新的条件输入控制。
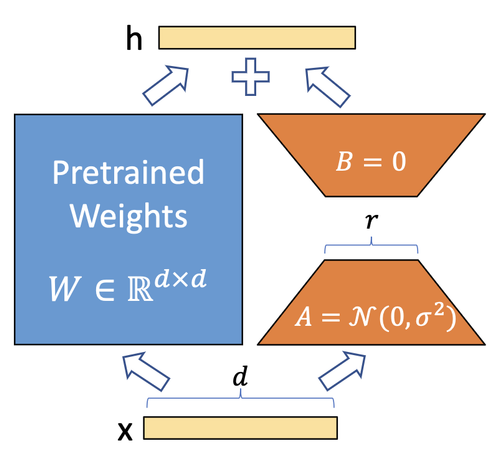
LoRA则是另一种参数孤立化策略。如P2,它利用低秩矩阵来替代原来全量参数进行训练,从而提升finetune的效率。
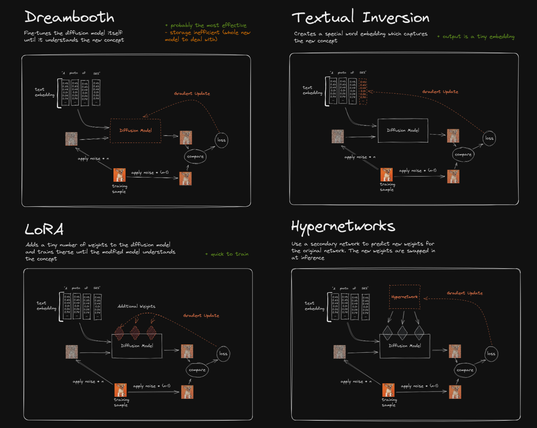
我们可以拿来和DreamBooth对比一下。P3是个很清晰的对比图。
对于DreamBooth来说,它是直接更新整个大模型的权重来让模型学习新概念的。虽然可以通过正则项避免遗忘,但是finetune后的模型依然非常大(和原模型一样大)。
而使用LoRA后,LoRA影响的只是其中一小部分(通过低秩矩阵叠加到大模型网络上)。所以finetune起来更快,更不吃资源,而且得到的finetune模型非常小,使用起来方便很多。
由于LoRA在结构上是独立于大模型的,所以它甚至有一个额外的好处是替换大模型可以得到不同的令人惊喜的结果。而且也非常方便进行模型融合。
在使用上来说,LoRA很像是模型的“插件”,你可以在基础模型上叠加你想要的效果,或者把各种你想要的效果加权组合叠在一起,可以产生很多令人惊喜的结果。
当然LoRA由于是finetune模型,所以画风会趋于单一,是好是坏见仁见智,在需要固定画风orID的时候能发挥令人惊喜的用处。