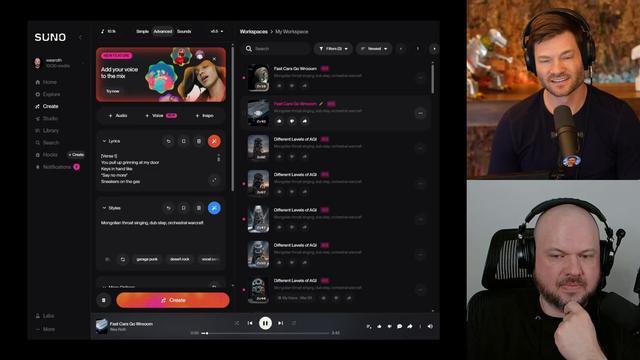
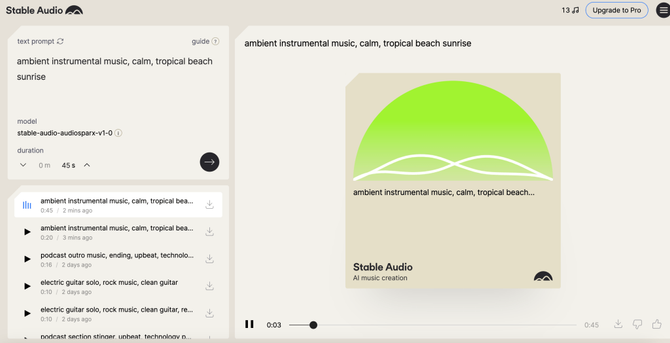
Hands on with AI audio generation: GAI voice, music, and sound effects
This is the second post in a series exploring the multimodal possibilities of generative AI. This series will take a detailed, hype-free look at text, image, audio, video, and code generation and explore the creative potential as well as the ethical concerns of GAI.
Although Generative AI isn't a new technology, it's definitely been having a hype moment since the release of ChatGPT in November 2022. Unfortunately, the focus has been squarely on the text-based chatbot at the exclusion of […]
https://leonfurze.com/2023/09/25/hands-on-with-ai-audio-generation-gai-voice-music-and-sound-effects/