Can time series (TS) #FoundationModels (FM) like Chronos zero-shot generalize to unseen #DynamicalSystems (DS)? #AI
No, they cannot!
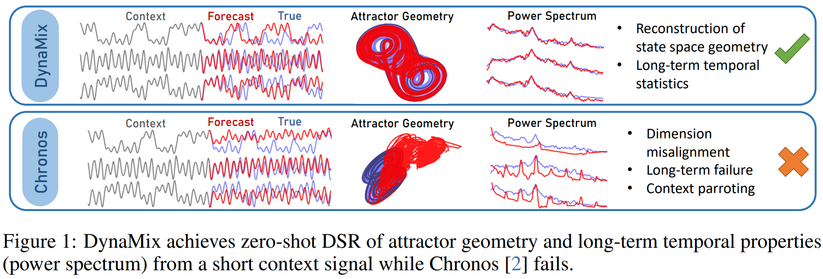
But *DynaMix* can, the first TS/DS foundation model based on principles of DS reconstruction, capturing the long-term evolution of out-of-domain DS: https://arxiv.org/pdf/2505.13192v1
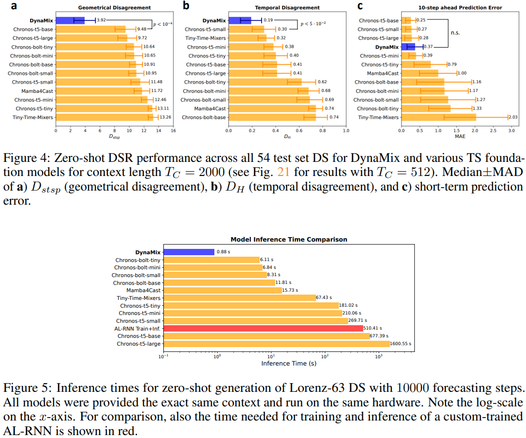
Unlike TS foundation models, DynaMix exhibits #ZeroShotLearning of long-term stats of unseen DS, incl. attractor geometry & power spectrum, w/o *any* re-training, just from a context signal.
It does so with only 0.1% of the parameters of Chronos & 10x faster inference times than the closest competitor.
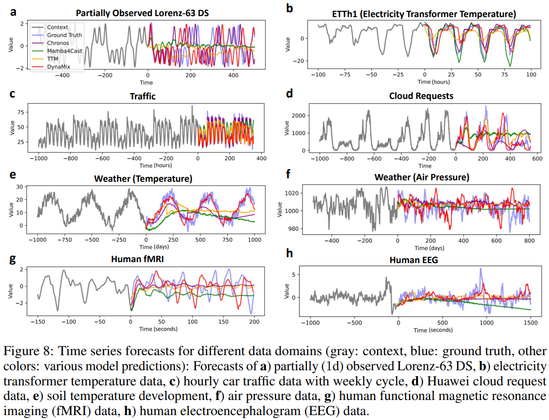
It often even outperforms TS FMs on forecasting diverse empirical time series, like weather, traffic, or medical data, typically used to train TS FMs.
This is surprising, cos DynaMix’ training corpus consists *solely* of simulated limit cycles & chaotic systems, no empirical data at all!
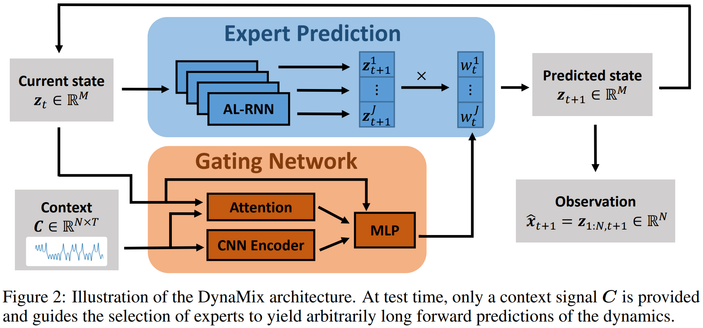
And no, it’s neither based on Transformers nor Mamba – it’s a new type of mixture-of-experts architecture based on the recently introduced AL-RNN (https://proceedings.neurips.cc/paper_files/paper/2024/file/40cf27290cc2bd98a428b567ba25075c-Paper-Conference.pdf), specifically trained for DS reconstruction.
Remarkably, DynaMix not only generalizes zero-shot to novel DS, but it can even generalize to new initial conditions and regions of state space not covered by the in-context information.
We dive a bit into the reasons why current time series FMs not trained for DS reconstruction fail, and conclude that a DS perspective on time series forecasting & models may help to advance the #TimeSeriesAnalysis field.