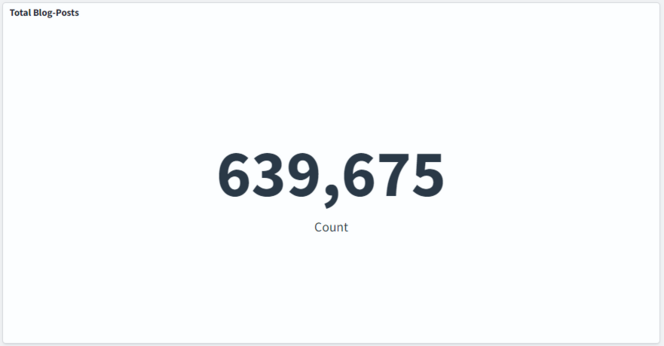
I let the #uselessinfrastructure run over the weekend.
It created and indexed over 600k blog posts with around 18k posts per hour.
Unfortunately my PC went on hibernate on Saturday. But despite that nice result.
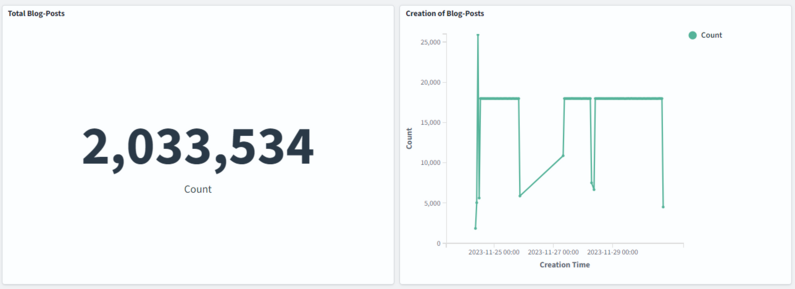
So after a week I got to over 2m indexed fake blog posts.
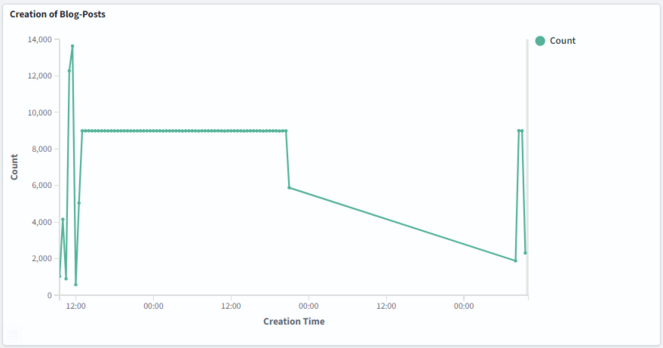
the #uselessinfrastructure ran smoothly creating and indexing around 18k posts per hour.
The holes in the graph are because my laptop went on hybernate 😄
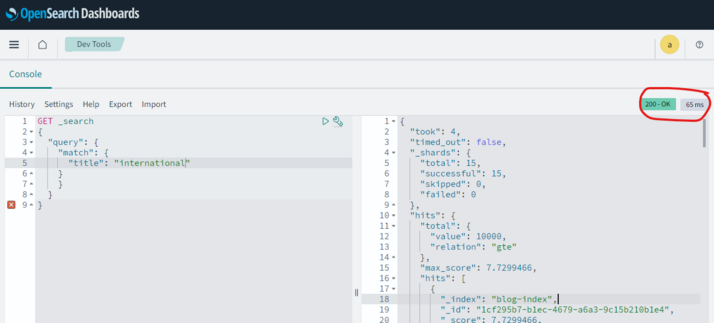
Searching the index is blazing fast . The results come in within >100ms
Conclusion:
This experiment shows for me, that not all use cases need a cluster. Sometimes, especially if you "just need a better search then the DB once" you can run #opensearch in a container...
I let the #uselessinfrastructure run over the weekend.
It created and indexed over 600k blog posts with around 18k posts per hour.
Unfortunately my PC went on hibernate on Saturday. But despite that nice result.
My #UselessInfrastructure is making progress. And I learned a lot about #docker, #dockercompose, #Kafka and #OpenSearch while setting it up.
I added also #KafkaUI to get some insights on the topics and what's going on under the hood in Kafka.
If you are interested in playing around with it, it's just a `git clone https://github.com/sebastian-muthwill/useless-infrastructure` and `docker compose up` away. 🤣
https://github.com/sebastian-muthwill/useless-infrastructure
#solutionarchitect #cloud #playground