От неизвестной схемы до защищённой БД: полный цикл защиты данных в Tantor Certified 17
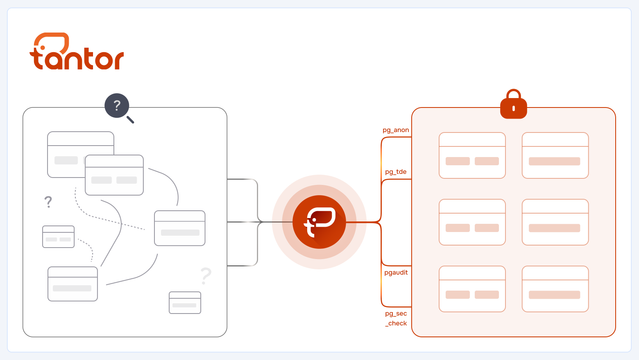
«Поднятие» унаследованного Postgres без специнструментов быстро превращается в головную боль: вас ждет ручной разбор схем, перелопачивание десятков таблиц и прочая невеселая археология - где лежат персональные данные, что за колонки, как это всё соотносится с 152-ФЗ… Один неверный шаг – и можно запросто упустить что-то важное. Встроенного защитного преобразования данных на диске нет, приходится либо городить огород на уровне приложений, либо создавать триггеры. Хранить ключи, тестировать производительность, поддерживать это всё, руками выставлять фильтры, думать, куда писать логи, как следить за аномалиями и так далее. Всё, что связано с безопасностью – проверять вручную. Любое изменение схемы — снова садись и аудируй заново. Времени уходить будет очень много, и неизвестно, какие грабли вылезут. В СУБД Tantor Certified то, что обычно делается на коленке, превращается в понятный и безопасный процесс, который подробно описывается в статье.
https://habr.com/ru/companies/tantor/articles/1006092/
#postgresql #postgres #tantor #tantor_postgres #tantor_certified #персональные_данные