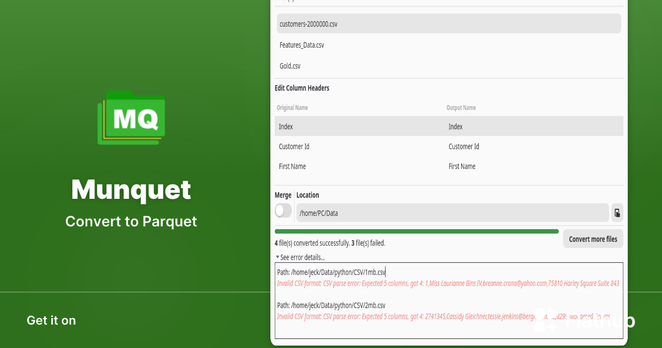
Munquet 0.2.1 just landed on Flathub 🚀
Fixed a small race condition when canceling a conversion — turns out the process could finish right before you clicked “Yes” 😅
Two lines later… all good.
https://flathub.org/en/apps/io.gitlab.zulfian1732.munquet
#Flatpak #GTK4 #OpenSource #Parquet #DataScience #Linux #Python #PyArrow