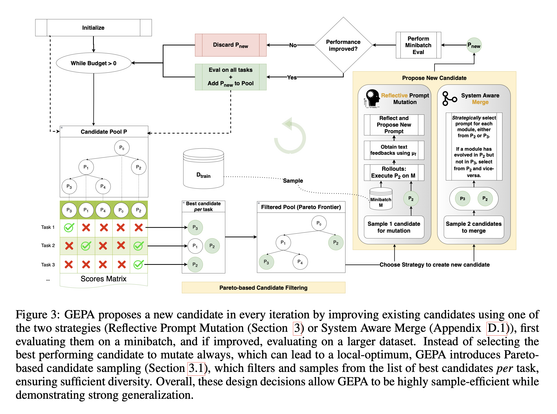
GEPA optimizes prompts in compound AI systems by reading failed trajectories in natural language and editing the prompt of the module that caused the failure. Across six tasks it beats GRPO by 6% on average, up to 20%, with up to 35x fewer rollouts. Reflection extracts per-module diagnosis from a trajectory. GRPO collapses the same trajectory into one scalar and spreads it across every token.
A huge LEAP forward for graph learning and topological deep learning: Juan is taking about our recent ICLR work on learnable positional encodings.
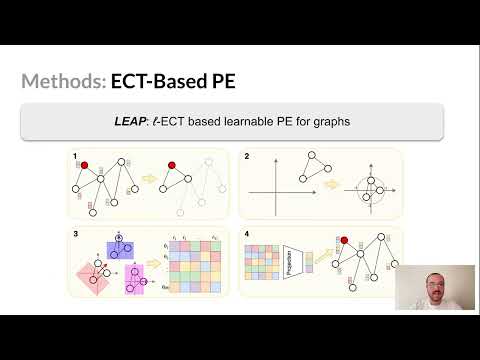
LEAP: Local ECT-Based Learnable Positional Encodings for Graphs
It was great to meet with you @[email protected] . I hope you are enjoying these last days of #ICLR2026 and this gorgeous city 😊🇧🇷




Not participating in #ICLR2026 this year (unfortunately) but I'm in town. Please ping me if you want to meet 😊🇧🇷
Scenes from a busy #ICLR2026 in Rio de Janeiro! We're excited to be connecting with researchers & exploring the latest advances in ML! 🇧🇷

#ICLR2026 paper✨️: Quantifying epistemic uncertainty of Blackbox classifiers, and link to better decisions
Calibration on steroids, qualifying full prediction uncertainty with no need for Bayes, and tuning individual decisions 👇

👋 Will you be at #ICLR2026?
Stop by our researchers' posters to learn more about their work!

Congratulations to the winners of the #ICLR2026 Outstanding Paper Award! It was an honour to chair the committee, the entire team did a great job. We recognized two outstanding papers and one honorable mention.
Check out the blog post for more: blog.iclr.cc/2026/04/23/a...

https://bsky.app/profile/ellisinstitute.fi/post/3mk3dusz6bk2d Our researchers are at #ICLR2026 with the latest machine learning advances. Check them out April 23-27 in Rio de Janeiro and on our site ➡️ https://www.ellisinstitute.fi/ellis-institute-finland-at-iclr-and-aistats-2026
@iclr-conf.bsky.social @csaalto.bsky.social @univhelsinkics.bsky.social @ellis.eu @samikaski.bsky.social #ELLISFinland #yliopisto

ELLIS Institute Finland (@ellisinstitute.fi)
Our researchers are at #ICLR2026 with the latest machine learning advances. Check them out April 23-27 in Rio de Janeiro and on our site ➡️ https://www.ellisinstitute.fi/ellis-institute-finland-at-iclr-and-aistats-2026 @iclr-conf.bsky.social @csaalto.bsky.social @univhelsinkics.bsky.social @ellis.eu @samikaski.bsky.social
Our researchers are at #ICLR2026 with the latest machine learning advances. Check them out April 23-27 in Rio de Janeiro and on our site ➡️ www.ellisinstitute.fi/ellis-instit...
@[email protected] @[email protected] @[email protected] @[email protected] @[email protected]
