RE: https://social.treehouse.systems/@nicolas17/116269606648203703
This is a great outcome on #ArchiveTeam #ArchiveBot. Thank you, Nicolás!
@jackyan For ArchiveBot, visit http://archivebot.com and look for your site on the left. On the right of the same line will be a string of gibberish.
Take it to #archivebot on Hackint IRC, post "!status <id>" and wait.
The bot will quickly respond with the nickname of the person who started the job, notifying them. At this point, you can describe your concern and wait for replies.
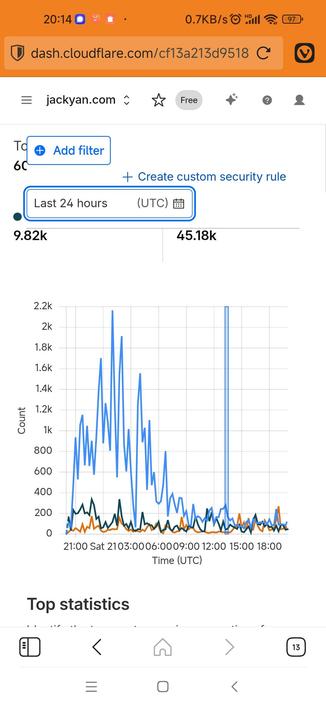
However, archiveteam_urls is a different beast. It's supervised but not actively controlled, and grabs all kinds of stuff without discretion - this sometimes invites unwanted attention of ISPs and law enforcement, but is considered worth the trouble.
Your homepage is linked from https://jyanet.com/lucire/ , which is considered to be a major, NYTimes-class newspaper and grabbed a lot as such: see 900_onlinenewspapers-com.txt in https://github.com/ArchiveTeam/urls-sources . I didn't dig further, but this one was almost certainly a semiautomatic process, perhaps involving Google searches for "news".
RE: https://social.treehouse.systems/@nicolas17/116269606648203703
This is a great outcome on #ArchiveTeam #ArchiveBot. Thank you, Nicolás!
Not the first time the #ArchiveTeam #ArchiveBot has been accused of excessive traffic.
https://utcc.utoronto.ca/~cks/space/blog/web/WebScrapingItsNotJustLoad?showcomments