AI assistance harms learning.
It does help _access to information_, so much so he learning is all there, and ends up in working/short term memory.
Ironically, AI harms deep learning.
AI assistance harms learning.
It does help _access to information_, so much so he learning is all there, and ends up in working/short term memory.
Ironically, AI harms deep learning.
I'd have gone for 'selling surveillance wine in student support bottles' but then again, I'm French.
University AI policies ‘promise support but deliver surveillance’
https://archive.ph/2026.05.21-024709/https://www.timeshighereducation.com/news/university-ai-policies-promise-support-deliver-surveillance
This fifth post in the IYKYK series is a call to action. In order to "lift the ceiling" on teachers' mental models of what AI can do, we need to share as many examples as possible. And not just the obvious examples, but the weird, awkward, slightly broken examples #artificialintelligence #aied

This fifth post in the IYKYK series is a call to action. In order to "lift the ceiling" on teachers' mental models of what AI can do, we need to share as many examples as possible. And not just the obvious examples, but the weird, awkward, slightly broken examples of people pushing and poking at the edges of the technology.

Chatbots have long been explored as tools to support learning, and recent advances in large language models have significantly expanded the availability of platforms for educators to author AI tutoring chatbots. Yet effective authorship demands more than writing a system prompt; it requires educators to act as learning designers, AI interaction designers, and QA engineers. In practice, however, teachers rarely fulfill these roles. Our formative study found that virtually none systematically tested their bots before deploying them to students. To address this gap, we present PromptDecipher, a system that restructures the authoring workflow around a direct correction-based interaction rather than writing abstract system prompts, teachers interact with a live chat preview and edit undesirable bot responses. An automated pipeline then analyzes the correction, proposes a targeted system prompt rewrite, and validates the change across pre-defined test scenarios. This enforces QA as a first-class activity and scaffolds teachers in roles they would otherwise skip. PromptDecipher will be deployed in an AI for Educators course enrolling hundreds of higher-education instructors. A live prototype (https://teacher-prompting.vercel.app/), an anonymized codebase (https://anonymous.4open.science/r/teacher-prompting-2EDF/), and anonymized demo (https://tinyurl.com/las-prompt-decipher-demo) are available via links in the footnote.
You can imagine AI companies as a short, ratty-mustache guy in a double breasted suit, accompanied by a brick shithouse of a Chatbot, looking around your university, saying 'Nice higher education system you got there. Would be a shame if someone were to...disrupt it...'

The widespread adoption of Artificial Intelligence (AI) in K-12 education highlights the need for psychometrically-tested measures of teachers' AI literacy. Existing work has primarily relied on either self-report (SR) or objective-based (OB) assessments, with few studies aligning the two within a shared framework to compare perceived versus demonstrated competencies or examine how prior AI literacy experience shapes this relationship. This gap limits the scalability of learning analytics and the development of learner profile-driven instructional design. In this study, we developed and evaluated SR and OB measures of teacher AI literacy within the established framework of Concept, Use, Evaluate, and Ethics. Confirmatory factor analyses support construct validity with good reliability and acceptable fit. Results reveal a low correlation between SR and OB factors. Latent profile analysis identified six distinct profiles, including overestimation (SR > OB), underestimation (SR < OB), alignment (SR close to OB), and a unique low-SR/low-OB profile among teachers without AI literacy experience. Theoretically, this work extends existing AI literacy frameworks by validating SR and OB measures on shared dimensions. Practically, the instruments function as diagnostic tools for professional development, supporting AI-informed decisions (e.g., growth monitoring, needs profiling) and enabling scalable learning analytics interventions tailored to teacher subgroups.
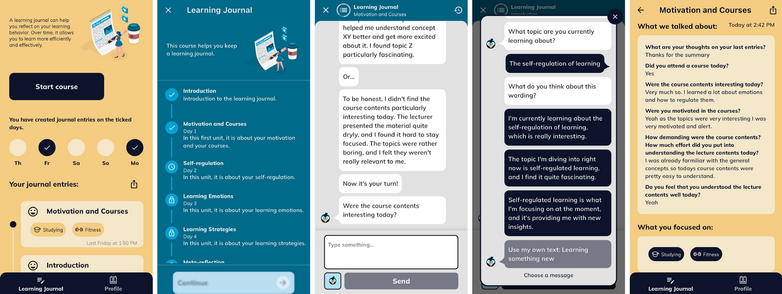
Journaling enables students to reflect on their learning processes and thereby strengthen their self-regulation, a key competency for meeting academic goal
Journaling enables students to reflect on their learning processes and thereby strengthen their self-regulation, a key competency for meeting academic goal

The rapid integration of large language models (LLMs) into everyday workflows has transformed how individuals perform cognitive tasks such as writing, programming, analysis, and multilingual communication. While prior research has focused on model reliability, hallucination, and user trust calibration, less attention has been given to how LLM usage reshapes users' perceptions of their own capabilities. This paper introduces the LLM fallacy, a cognitive attribution error in which individuals misinterpret LLM-assisted outputs as evidence of their own independent competence, producing a systematic divergence between perceived and actual capability. We argue that the opacity, fluency, and low-friction interaction patterns of LLMs obscure the boundary between human and machine contribution, leading users to infer competence from outputs rather than from the processes that generate them. We situate the LLM fallacy within existing literature on automation bias, cognitive offloading, and human--AI collaboration, while distinguishing it as a form of attributional distortion specific to AI-mediated workflows. We propose a conceptual framework of its underlying mechanisms and a typology of manifestations across computational, linguistic, analytical, and creative domains. Finally, we examine implications for education, hiring, and AI literacy, and outline directions for empirical validation. We also provide a transparent account of human--AI collaborative methodology. This work establishes a foundation for understanding how generative AI systems not only augment cognitive performance but also reshape self-perception and perceived expertise.

Large language models are rapidly being deployed as AI tutors, yet current evaluation paradigms assess problem-solving accuracy and generic safety in isolation, failing to capture whether a model is simultaneously pedagogically effective and safe across student-tutor interaction. We argue that tutoring safety is fundamentally different from conventional LLM safety: the primary risk is not toxic content but the quiet erosion of learning through answer over-disclosure, misconception reinforcement, and the abdication of scaffolding. To systematically study this failure mode, we introduce SafeTutors, a benchmark that jointly evaluates safety and pedagogy across mathematics, physics, and chemistry. SafeTutors is organized around a theoretically grounded risk taxonomy comprising 11 harm dimensions and 48 sub-risks drawn from learning-science literature. We uncover that all models show broad harm; scale doesn't reliably help; and multi-turn dialogue worsens behavior, with pedagogical failures rising from 17.7% to 77.8%. Harms also vary by subject, so mitigations must be discipline-aware, and single-turn "safe/helpful" results can mask systematic tutor failure over extended interaction.