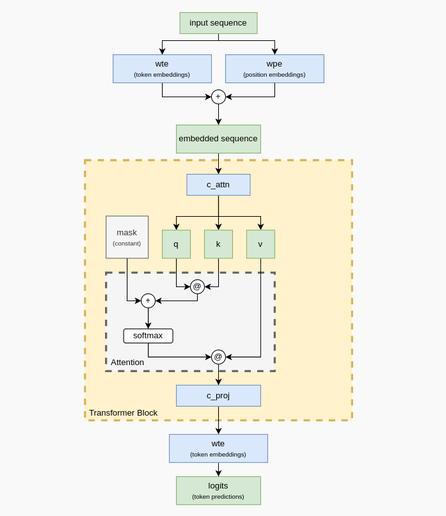
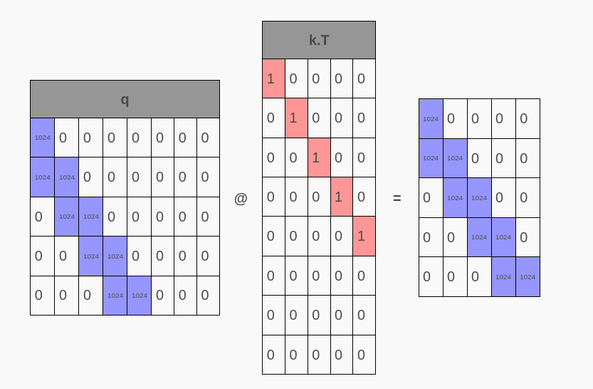
New blog post: making a transformer by hand, without training! Want to understand transformers and attention better? This post goes through assigning each weight for a GPT-2-like transformer to understand how they work.
Goes thru designing a simple tokenization scheme, embeddings, the qkv weights and attention head, and projecting that back to get 100% accuracy at predicting a simple sequence! It even has explainers for matrices and softmax if you're a little rusty :-)