Fontra has shaping debugger! This is super useful.
Thanks @fontra

Principal engineer at Wikimedia Foundation.
Interests: Language computing, Type design, Linguistics, Indian languages, Malayalam, Free and open source
Designer of Manjari, Chilanka, Nupuram & Malini Malayalam typefaces.
| Website | https://thottingal.in |
Fontra has shaping debugger! This is super useful.
Thanks @fontra
It is 2026 and terminal applications can't render complex scripts. As TUI applications are getting popularity, this is a significant limitation.
I looked in to the OSC 66 protocol in Kitty terminal and wrote a small tool that will make complex scripts like Malayalam render better in terminal.
Article: https://thottingal.in/blog/2026/03/22/complex-scripts-in-terminal/. It is now readable, but not optimal because of the discrete cells allocated for each glyph.

wikipedia-article-transform - a cli tool and agentic skill to work with Wikipedia articles in token efficient way. Transform the html content into content focussed Markdown or plain text or structured json. Can save about 90% of tokens.
https://thottingal.in/blog/2026/03/14/wikipedia-article-transform/
We are witnessing a resurgence and evolution of Command Line Interfaces (CLIs), accelerated by AI agents. Text-based, scriptable CLI tools work very well with LLM-based workflows. Accessing Wikipedia articles during an agent session is common. Usually, a webfetch call is used to get the HTML for a page from a URL like https://en.wikipedia.org/wiki/2026_Winter_Olympics. That works, and LLMs are smart enough to read HTML. But there is a cost: HTML is for rendering, so the model must ignore a lot of non-content markup to get to the useful text. i That increases token usage and adds context noise. Can we improve this?
Two new resources for natural language processing researchers and developers:
* wikisentences - A Rust-based tool for extracting sentence datasets from Wikipedia dumps in any language
* ml-wiki-sentences - A dataset of 2.25 million Malayalam sentences extracted from Wikipedia, now available on HuggingFace, prepared using the above tool.
I’m excited to announce two new resources for natural language processing researchers and developers: wikisentences - A Rust-based tool for extracting sentence datasets from Wikipedia dumps in any language ml-wiki-sentences - A dataset of 2.25 million Malayalam sentences extracted from Wikipedia, now available on HuggingFace, prepared using the above tool. The Wikisentences Tool The wikisentences project provides a complete pipeline for creating sentence datasets from Wikipedia content: Core Technology wiki-html-text-extractor (Rust) - Uses tree-sitter-html to parse article HTML and extract clean plain text sentencex (Rust) - Handles accurate sentence segmentation across languages. See my recent article about this library Four-Stage Pipeline Download enterprise HTML dumps from WikimediaThere is no recent html dumps for wikipedia, except this one year old dump Convert JSON dumps to Parquet format (id, name, url, language, html) Extract plain text from HTML (id, url, name, text) Segment text into sentences (id, url, name, sentence, sentence_index) Each stage is handled by a separate Python script, with the heavy lifting done by efficient Rust binaries. The pipeline is designed to be memory-efficient, streaming data between stages without writing intermediate files to disk.
How to identify and annotate sentences in an HTML page?
https://thottingal.in/blog/2026/03/07/html-sentence-segmentation/

Using the tokenizer I introduced yesterday, I built a small language model that can generate text at 1000 tokens/second. It's a Markov chain model with trigram context (context of 3 nearby words). The output text is nonsense enough 😄
Try it here: https://malgen.thottingal.in/
Article: https://thottingal.in/blog/2026/02/28/malayalam-markov-chain/
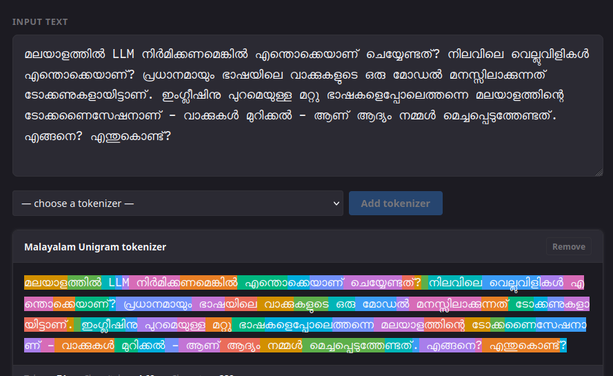
What does it take to get Large Language Models trained in low-resource languages? I analyse this problem from first principles, using my mother tongue, Malayalam, as a case study.
I trained a tokenizer and evaluated its performance against other tokenizers. I analysed the challenges that need to be solved to get a functional LLM. In other words, this is also a story of why LLMs work in languages like English.
The Broken Token: Tokenization for Malayalam Language Models
https://thottingal.in/blog/2026/02/27/malayalam-tokenizer-llm/
I wrote about Rust implementation of Raph Leviens two-parameter curve fitting,
and how I implemented a variable offset outline for the curves and made it interpolatable to use in typeface design.
https://thottingal.in/blog/2026/02/20/var-interpolatable-smooth-curves/
Published svg2glif - a Rust crate to convert SVG vector graphics into UFO (Unified Font Object) GLIF format, making it easy to incorporate SVG artwork into font development workflows. https://crates.io/crates/svg2glif/
I am migrating my python based type engineering workflow to rust (fontmake -> fontc) and this is one of the tool I need.
