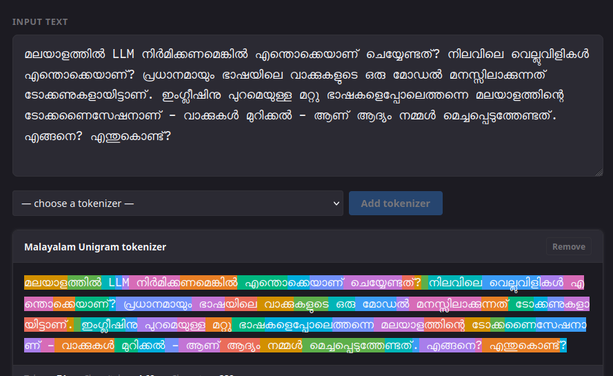
What does it take to get Large Language Models trained in low-resource languages? I analyse this problem from first principles, using my mother tongue, Malayalam, as a case study.
I trained a tokenizer and evaluated its performance against other tokenizers. I analysed the challenges that need to be solved to get a functional LLM. In other words, this is also a story of why LLMs work in languages like English.
The Broken Token: Tokenization for Malayalam Language Models
https://thottingal.in/blog/2026/02/27/malayalam-tokenizer-llm/