The most popular Arxiv link during the weekend (via ymatias@twitter):
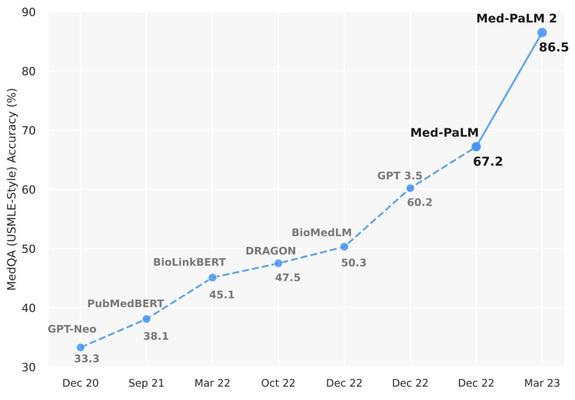
How did our medical #LLM, Med-PaLM 2, become the first to perform at “expert” level on U.S. Medical Licensing Exam-style questions? Check out our new paper: https://t.co/dyMoJVSJyE https://t.co/nM6pc3URvu
https://twitter.com/ymatias/status/1659730065515577346
The most popular Arxiv link yesterday (via ShunyuYao12@twitter):
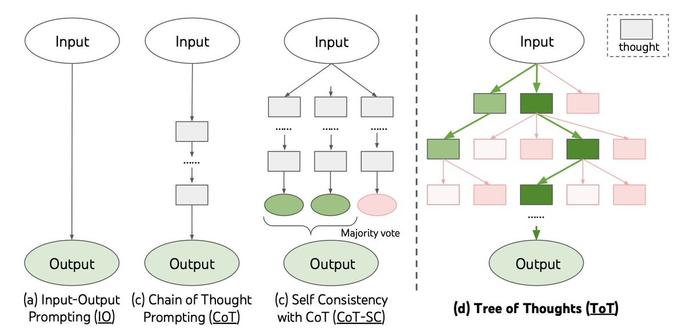
Still use ⛓️Chain-of-Thought (CoT) for all your prompting? May be underutilizing LLM capabilities🤠
Introducing 🌲Tree-of-Thought (ToT), a framework to unleash complex & general problem solving with LLMs, through a deliberate ‘System 2’ tree search.
https://t.co/V6hjbUNjbt https://t.co/IaZZdVeaTW
https://twitter.com/ShunyuYao12/status/1659357547474681857

Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role. To surmount these challenges, we introduce a new framework for language model inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting language models, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices. Our experiments show that ToT significantly enhances language models' problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4% of tasks, our method achieved a success rate of 74%. Code repo with all prompts: https://github.com/princeton-nlp/tree-of-thought-llm.
The most popular Arxiv link yesterday (via tlngy@twitter):
I’m stoked to release my PhD work 🥳
https://t.co/43aCABWL8u
We found that neutrophils swell (they drink H2O💧!) when they start to move. We used a genome-wide screen to figure out how they swell and found that stopping it makes cells much slower!
🐇-💧=🐢
🐢immune cell = 🤒 https://t.co/jumx18kozI
https://twitter.com/tlngy/status/1658964520608382976
The most popular Arxiv link yesterday (via AziziShekoofeh@twitter):
Excited to share our new pre-print on "Med-PaLM 2", highlighting our progress towards achieving expert-level medical question answering performance!
Link: https://t.co/12rBwQSnqP https://t.co/WhOk45mZ8Q
https://twitter.com/AziziShekoofeh/status/1658659343087304705
The most popular Arxiv link yesterday (via stevenhoi@twitter):
Introducing 🔥CodeT5+🔥, a new family of open-source code LLMs for both code understanding and generation, achieved new SoTA code generation performance on HumanEval, surpassing all the open-source code LLMs.
Paper: https://t.co/apxl03WvNc
Code: https://t.co/nHTaIGIEmm
(1/n) https://t.co/YR7cp2P2Yn
https://twitter.com/stevenhoi/status/1658270266424975361
The most popular Arxiv link yesterday (via _akhaliq@twitter):
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
abs: https://t.co/yqzduI4EpP
paper page: https://t.co/h6pM6L0UIv https://t.co/S2kPHVkD6m
https://twitter.com/_akhaliq/status/1657919671092539394


MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
Autoregressive transformers are spectacular models for short sequences but
scale poorly to long sequences such as high-resolution images, podcasts, code,
or books. We proposed Megabyte, a multi-scale decoder architecture that enables
end-to-end differentiable modeling of sequences of over one million bytes.
Megabyte segments sequences into patches and uses a local submodel within
patches and a global model between patches. This enables sub-quadratic
self-attention, much larger feedforward layers for the same compute, and
improved parallelism during decoding -- unlocking better performance at reduced
cost for both training and generation. Extensive experiments show that Megabyte
allows byte-level models to perform competitively with subword models on long
context language modeling, achieve state-of-the-art density estimation on
ImageNet, and model audio from raw files. Together, these results establish the
viability of tokenization-free autoregressive sequence modeling at scale.
The most popular Arxiv link during the weekend (via _akhaliq@twitter):
HACK: Learning a Parametric Head and Neck Model for High-fidelity Animation
abs: https://t.co/TeafvDiMmW
paper page: https://t.co/1TJeGslkhZ https://t.co/qfQH8GmQ79
https://twitter.com/_akhaliq/status/1657806182306676737
HACK: Learning a Parametric Head and Neck Model for High-fidelity Animation
Significant advancements have been made in developing parametric models for
digital humans, with various approaches concentrating on parts such as the
human body, hand, or face. Nevertheless, connectors such as the neck have been
overlooked in these models, with rich anatomical priors often unutilized. In
this paper, we introduce HACK (Head-And-neCK), a novel parametric model for
constructing the head and cervical region of digital humans. Our model seeks to
disentangle the full spectrum of neck and larynx motions, facial expressions,
and appearance variations, providing personalized and anatomically consistent
controls, particularly for the neck regions. To build our HACK model, we
acquire a comprehensive multi-modal dataset of the head and neck under various
facial expressions. We employ a 3D ultrasound imaging scheme to extract the
inner biomechanical structures, namely the precise 3D rotation information of
the seven vertebrae of the cervical spine. We then adopt a multi-view
photometric approach to capture the geometry and physically-based textures of
diverse subjects, who exhibit a diverse range of static expressions as well as
sequential head-and-neck movements. Using the multi-modal dataset, we train the
parametric HACK model by separating the 3D head and neck depiction into various
shape, pose, expression, and larynx blendshapes from the neutral expression and
the rest skeletal pose. We adopt an anatomically-consistent skeletal design for
the cervical region, and the expression is linked to facial action units for
artist-friendly controls. HACK addresses the head and neck as a unified entity,
offering more accurate and expressive controls, with a new level of realism,
particularly for the neck regions. This approach has significant benefits for
numerous applications and enables inter-correlation analysis between head and
neck for fine-grained motion synthesis and transfer.
The most popular Arxiv link yesterday (via DulwichQuantum@twitter):
A breakthrough result that finally resolves the longstanding author ordering problem.
https://t.co/jIMT9f1FBZ https://t.co/waMysbMWXa
https://twitter.com/DulwichQuantum/status/1656980286993997824

Every Author as First Author
We propose a new standard for writing author names on papers and in bibliographies, which places every author as a first author -- superimposed. This approach enables authors to write papers as true equals, without any advantage given to whoever's name happens to come first alphabetically (for example). We develop the technology for implementing this standard in LaTeX, BibTeX, and HTML; show several examples; and discuss further advantages.
The most popular Arxiv link yesterday (via _akhaliq@twitter):
Relightify: Relightable 3D Faces from a Single Image via Diffusion Models
abs: https://t.co/4XfU1XvlkL
paper page: https://t.co/JYSJsbQmxN https://t.co/f3vS9evtzI
https://twitter.com/_akhaliq/status/1656467161693519873
Relightify: Relightable 3D Faces from a Single Image via Diffusion Models
Following the remarkable success of diffusion models on image generation,
recent works have also demonstrated their impressive ability to address a
number of inverse problems in an unsupervised way, by properly constraining the
sampling process based on a conditioning input. Motivated by this, in this
paper, we present the first approach to use diffusion models as a prior for
highly accurate 3D facial BRDF reconstruction from a single image. We start by
leveraging a high-quality UV dataset of facial reflectance (diffuse and
specular albedo and normals), which we render under varying illumination
settings to simulate natural RGB textures and, then, train an unconditional
diffusion model on concatenated pairs of rendered textures and reflectance
components. At test time, we fit a 3D morphable model to the given image and
unwrap the face in a partial UV texture. By sampling from the diffusion model,
while retaining the observed texture part intact, the model inpaints not only
the self-occluded areas but also the unknown reflectance components, in a
single sequence of denoising steps. In contrast to existing methods, we
directly acquire the observed texture from the input image, thus, resulting in
more faithful and consistent reflectance estimation. Through a series of
qualitative and quantitative comparisons, we demonstrate superior performance
in both texture completion as well as reflectance reconstruction tasks.
The most popular Arxiv link yesterday (via srush_nlp@twitter):
Pretraining without Attention (https://t.co/Y2P32MheXc) - BiGS is alternative to BERT trained on up to 4096 tokens.
Attention can be overkill. Below shows *every* word-word interaction for every sentence over 23 layers of BiGS (no heads, no n^2). https://t.co/bZVkaXH2r7
https://twitter.com/srush_nlp/status/1656303656004624386

Pretraining Without Attention
Transformers have been essential to pretraining success in NLP. While other
architectures have been used, downstream accuracy is either significantly
worse, or requires attention layers to match standard benchmarks such as GLUE.
This work explores pretraining without attention by using recent advances in
sequence routing based on state-space models (SSMs). Our proposed model,
Bidirectional Gated SSM (BiGS), combines SSM layers with a multiplicative
gating architecture that has been effective in simplified sequence modeling
architectures. The model learns static layers that do not consider pair-wise
interactions. Even so, BiGS is able to match BERT pretraining accuracy on GLUE
and can be extended to long-form pretraining of 4096 tokens without
approximation. Analysis shows that while the models have similar average
accuracy, the approach has different inductive biases than BERT in terms of
interactions and syntactic representations. All models from this work are
available at https://github.com/jxiw/BiGS.