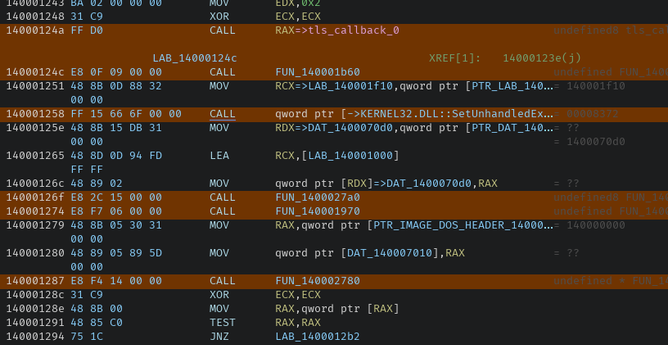
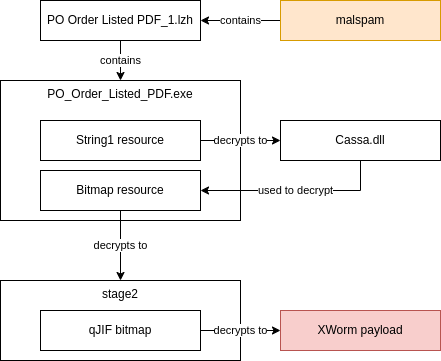
Ghidralib development continues: py3 support, binary/asm patching, and symbolic propagation: https://github.com/msm-code/ghidralib. I also write docs for people who want to try it. Newest chapter: emulation https://msm-code.github.io/ghidralib/emulator/
#ghidra #reverseengineering
#ghidra #reverseengineering