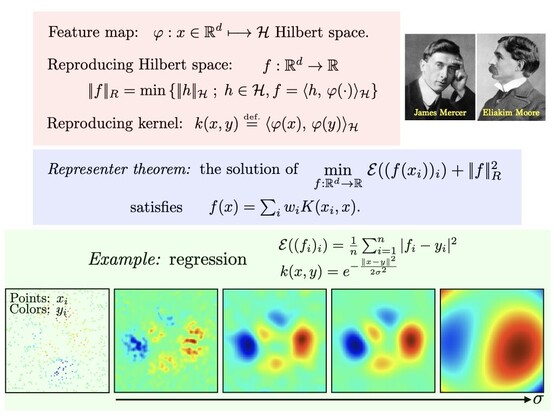
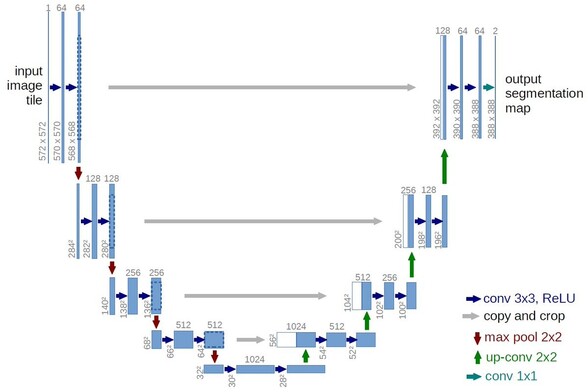
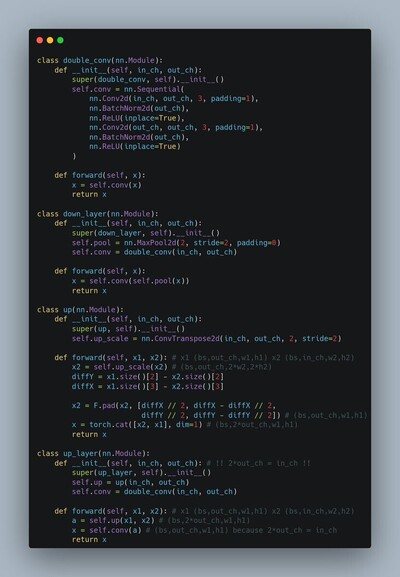
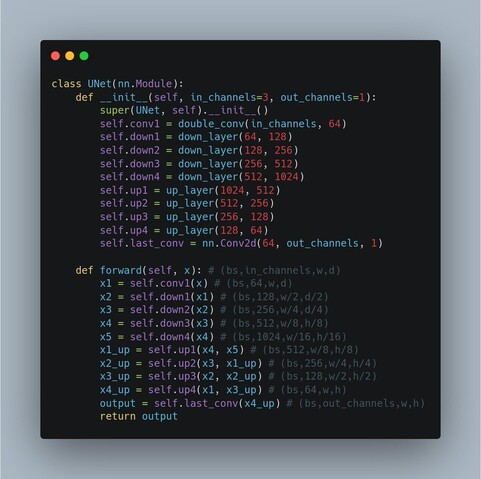
Reproducing Kernel Hilbert spaces define norms on functions so that solutions of regularized fitting problems are linear sum of kernel functions. Defines non-parametric learning methods (complexity scales with input). https://en.wikipedia.org/wiki/Reproducing_kernel_Hilbert_space