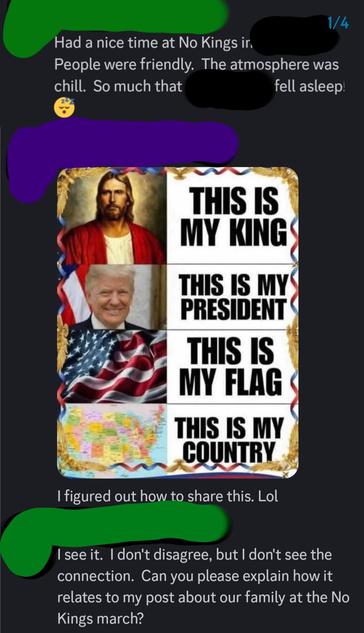
#Thanksgiving is coming! For many, that means politico-talks w/ #MAGA fam
Sharing a recent convo, to show how they can be less-awkward/more-effective
Keys
* Ask questions - engage left brain
* Establish trust - take down defenses
* Focus - ignore, call out distractions
* NO debate, compromise, or appease
* Bonus lesson: manipulation in news/socials
IRL, they ack'ed they were wrong about the protests. Small win, but progress!
Would love to hear others' experiences in replies
🙏Please boost 🤙