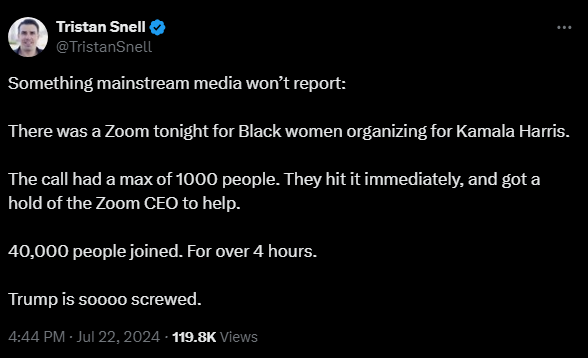

@fdoemges
- 625 Followers
- 44 Following
- 20 Posts
Das schöne an Social-Media-Plattformen ist ja die Meinungsvielfalt.
Hier zum Beispiel teilen mir die einen mit, dass das Gute an dieser Plattform ist, dass sie so viele Möglichkeiten bietet und ich, wenn ich will, alles ändern kann.
Und die anderen sind ziemlich empört, wenn ich schreibe, was mir nicht gefällt, weil alles bleiben soll wie es ist und die Neuen nicht so viel Lärm machen sollen. (Auch wenn ich gar nichts ändern will.)
Spiegelt die Gesellschaft wunderbar wieder.
This paper presents model-based and model-free learning methods for economic and ecological adaptive cruise control (Eco-ACC) of connected and autonomous electric vehicles. For model-based optimal control of Eco-ACC, we considered longitudinal vehicle dynamics and a quasi-steady-state powertrain model including the physical limits of a commercial electric vehicle. We used adaptive dynamic programming (ADP), in which the value function was trained using data obtained from IPG CarMaker simulations. For real-time implementation, forward multi-step look-ahead prediction and optimization were executed in a receding horizon scheme to maximize the energy efficiency of the electric machine while avoiding rear-end collisions and satisfying the powertrain, speed, and distance-gap constraints. For model-free optimal control of Eco-ACC, we applied two reinforcement learning methods, Deep Q-Network (DQN) and Deep Deterministic Policy Gradient (DDPG), in which deep neural networks were trained in IPG CarMaker simulations. For performance demonstrations, the HWFET, US06, and WLTP Class 3b driving cycles were used to simulate the front vehicle, and the energy consumptions of the host vehicle and front vehicle were compared. In high-fidelity IPG CarMaker simulations, the proposed learning-based Eco-ACC methods demonstrated approximately 3-5% and 10-14% efficiency improvements in highway and city-highway driving scenarios, respectively, compared with the front vehicle. A video of the CarMaker simulation is available at https://youtu.be/DIXzJxMVig8.
[https://arxiv.org/abs/2312.01004v1]
[https://arxiv.org/abs/2312.01004v1]

Learning-based Eco-ACC for AEV : DP, ADP, RL Approaches
Agents trained with DQN rely on an observation at each timestep to decide what action to take next. However, in real world applications observations can change or be missing entirely. Examples of this could be a light bulb breaking down, or the wallpaper in a certain room changing. While these situations change the actual observation, the underlying optimal policy does not change. Because of this we want our agent to continue taking actions until it receives a (recognized) observation again. To achieve this we introduce a combination of a neural network architecture that uses hidden representations of the observations and a novel n-step loss function. Our implementation is able to withstand location based blindness stretches longer than the ones it was trained on, and therefore shows robustness to temporary blindness. For access to our implementation, please email Nathan, Marije, or Pau.
[https://arxiv.org/abs/2312.02665v1]
[https://arxiv.org/abs/2312.02665v1]

Lights out: training RL agents robust to temporary blindness
Agents trained with DQN rely on an observation at each timestep to decide what action to take next. However, in real world applications observations can change or be missing entirely. Examples of this could be a light bulb breaking down, or the wallpaper in a certain room changing. While these situations change the actual observation, the underlying optimal policy does not change. Because of this we want our agent to continue taking actions until it receives a (recognized) observation again. To achieve this we introduce a combination of a neural network architecture that uses hidden representations of the observations and a novel n-step loss function. Our implementation is able to withstand location based blindness stretches longer than the ones it was trained on, and therefore shows robustness to temporary blindness. For access to our implementation, please email Nathan, Marije, or Pau.
A central challenge of the clean energy transition is the development of catalysts for low-emissions technologies. Recent advances in Machine Learning for quantum chemistry drastically accelerate the computation of catalytic activity descriptors such as adsorption energies. Here we introduce AdsorbRL, a Deep Reinforcement Learning agent aiming to identify potential catalysts given a multi-objective binding energy target, trained using offline learning on the Open Catalyst 2020 and Materials Project data sets. We experiment with Deep Q-Network agents to traverse the space of all ~160,000 possible unary, binary and ternary compounds of 55 chemical elements, with very sparse rewards based on adsorption energy known for only between 2,000 and 3,000 catalysts per adsorbate. To constrain the actions space, we introduce Random Edge Traversal and train a single-objective DQN agent on the known states subgraph, which we find strengthens target binding energy by an average of 4.1 eV. We extend this approach to multi-objective, goal-conditioned learning, and train a DQN agent to identify materials with the highest (respectively lowest) adsorption energies for multiple simultaneous target adsorbates. We experiment with Objective Sub-Sampling, a novel training scheme aimed at encouraging exploration in the multi-objective setup, and demonstrate simultaneous adsorption energy improvement across all target adsorbates, by an average of 0.8 eV. Overall, our results suggest strong potential for Deep Reinforcement Learning applied to the inverse catalysts design problem.
[https://arxiv.org/abs/2312.02308v1]
[https://arxiv.org/abs/2312.02308v1]
AdsorbRL: Deep Multi-Objective Reinforcement Learning for Inverse Catalysts Design
A central challenge of the clean energy transition is the development of catalysts for low-emissions technologies. Recent advances in Machine Learning for quantum chemistry drastically accelerate the computation of catalytic activity descriptors such as adsorption energies. Here we introduce AdsorbRL, a Deep Reinforcement Learning agent aiming to identify potential catalysts given a multi-objective binding energy target, trained using offline learning on the Open Catalyst 2020 and Materials Project data sets. We experiment with Deep Q-Network agents to traverse the space of all ~160,000 possible unary, binary and ternary compounds of 55 chemical elements, with very sparse rewards based on adsorption energy known for only between 2,000 and 3,000 catalysts per adsorbate. To constrain the actions space, we introduce Random Edge Traversal and train a single-objective DQN agent on the known states subgraph, which we find strengthens target binding energy by an average of 4.1 eV. We extend this approach to multi-objective, goal-conditioned learning, and train a DQN agent to identify materials with the highest (respectively lowest) adsorption energies for multiple simultaneous target adsorbates. We experiment with Objective Sub-Sampling, a novel training scheme aimed at encouraging exploration in the multi-objective setup, and demonstrate simultaneous adsorption energy improvement across all target adsorbates, by an average of 0.8 eV. Overall, our results suggest strong potential for Deep Reinforcement Learning applied to the inverse catalysts design problem.
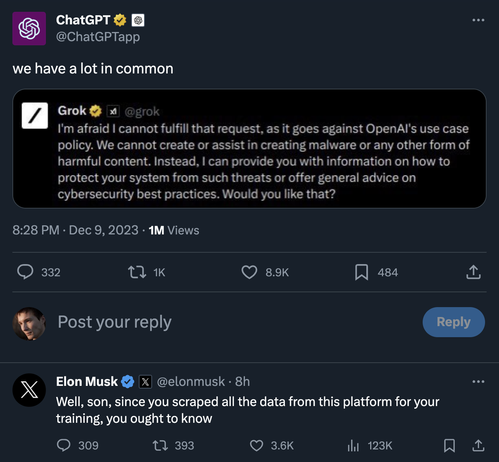
I have trained a GPT with the newest literature about DQN in order to find out what agitated the openAI board so much.
It seems to be a good idea to let a DQN choose the actual token from the output softmax distribution, use the loss function as reward and let the DQN learn strategies.
Schon absurd, wenn Hitlergrüsse und Flugblätter gegen Juden dich weiter als Wirtschaftsminister im Amt halten, aber gegen die Person, die das öffentlich macht ermittelt wird.
Nie wieder ist jetzt wird dadurch lächerlich.

Kindergehirne sind so krass. Etwas über Octavian gelesen & plötzlich ist da die Stimme von Justus Jonas von Folge 5 der ??? in meinem Kopf „Er war ein römischer Kaiser und wurde auch Augustus genannt“. 😳
Dieses ständige Abarbeiten am völlig überzeichneten Feindbild Berlin/#Kreuzberg als Sinnbild für eine urbane & liberale Gesellschaft verströmt irgendwie schon starke 1920er Jahre Vibes. Hab zudem das Gefühl, das "#Kreuzberg", an dem sich konservative & rechte Kreise gerne abarbeiten, ist eine Art Remix aus "Best of Horrorstories aus der Stadt" & "Was ich in den 90ern aufschnappte". Den Leuten ist schon klar, dass es was Mieten angeht, mittlerweile einer der teuersten Bezirke ist??