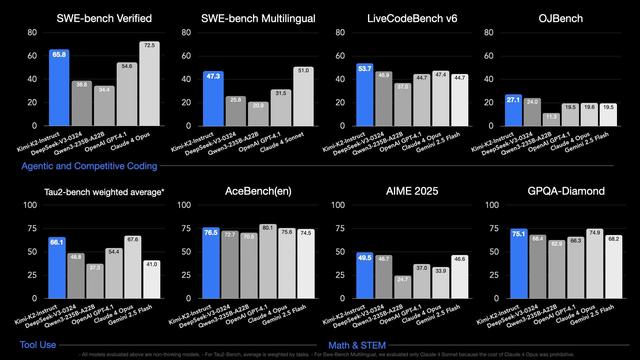
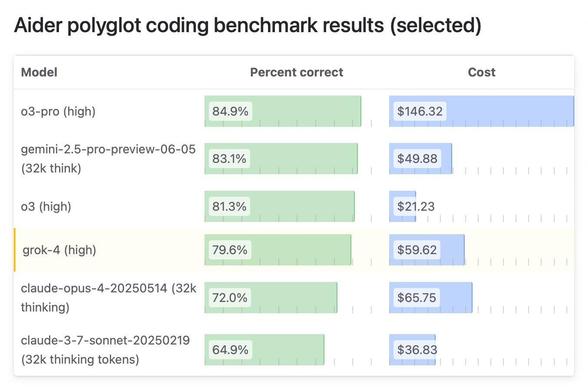
People I respect are speculating that OpenAI is pushing back their open-source release due to Kimi K2. It does strike me that this is what Llama 4 was supposed to be; a massive, impressive open-source MoE model that can form the basis for a new generation of agentic AI applications