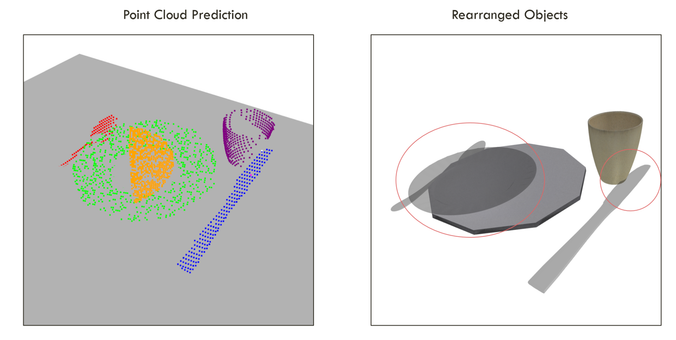
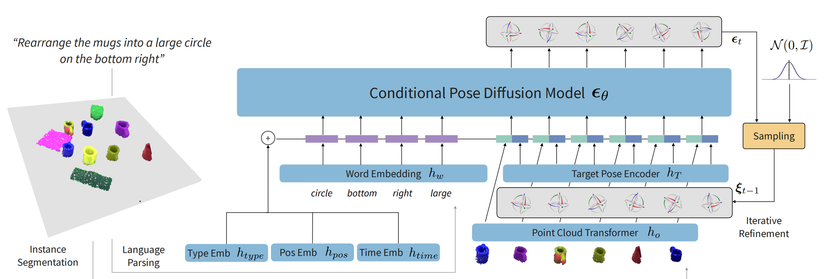
Combine multimodal transformers with diffusion models to build complex physically realistic structures in the real world! Excited to share our newest work, StructDiffusion:
- paper: https://arxiv.org/abs/2211.04604
- website: http://weiyuliu.com/StructDiffusion/
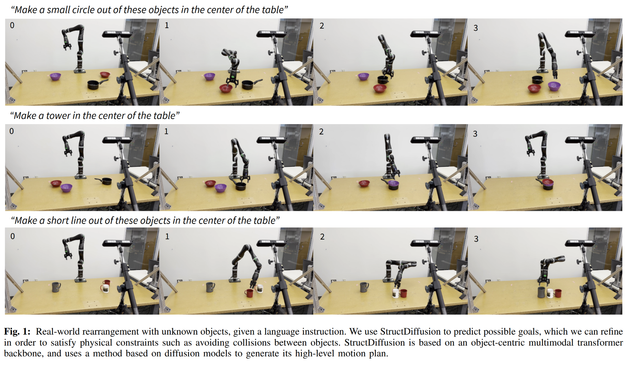
We train on simulated data + templated language to create structures from 4 different broad classes: lines, circles, table settings, and towers. The challenge is making sure that we can actually place these without collisions when we don't know objects.
StructDiffusion: Object-Centric Diffusion for Semantic Rearrangement of Novel Objects
Robots operating in human environments must be able to rearrange objects into semantically-meaningful configurations, even if these objects are previously unseen. In this work, we focus on the problem of building physically-valid structures without step-by-step instructions. We propose StructDiffusion, which combines a diffusion model and an object-centric transformer to construct structures out of a single RGB-D image based on high-level language goals, such as "set the table." Our method shows how diffusion models can be used for complex multi-step 3D planning tasks. StructDiffusion improves success rate on assembling physically-valid structures out of unseen objects by on average 16% over an existing multi-modal transformer model, while allowing us to use one multi-task model to produce a wider range of different structures. We show experiments on held-out objects in both simulation and on real-world rearrangement tasks. For videos and additional results, check out our website: http://weiyuliu.com/StructDiffusion/.