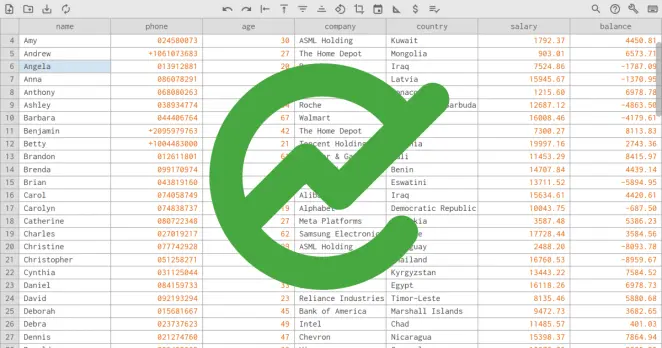
I am always surprised to see how, against all odds, CSV files remain the backbone of data ingestion. What is even more surprising is how difficult it is to simply look at or quickly edit them without breaking something. So I built:
https://github.com/CedricBonjour/nanocell-csv
Coded with ❤️
I want to shape it around actual data engineering workflows. What feature would make this an instant bookmark for you?
like it ? Feel free to drop a star or break it with some of your worst datasets and open an issue!