Advances in temporal graph reasoning to be presented at #ECAI
Researchers from the AI Institute at the University of Stuttgart @Uni_Stuttgart will present a paper tackling key challenges in temporal graph learning. The work, titled “Full-History Graphs with Edge-Type Decoupled Networks for Temporal Reasoning,” will be presented at #ECAI2025, a premier conference in artificial intelligence.
Full-History Graphs with Edge-Type Decoupled Networks for Temporal Reasoning
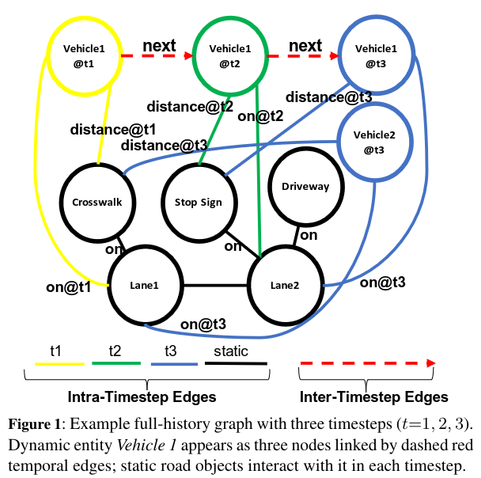
Temporal graphs are key to understanding dynamic systems—from traffic flow to financial fraud. ETDNet introduces a dual-branch temporal graph neural network that decouples spatial (intra-frame) and temporal (inter-frame) edges.
This design avoids over-smoothing and allows effective long-range reasoning. ETDNet improves driver-intention prediction (75.6% joint accuracy on Waymo) and illicit-transfer detection (88.1% F1 on Elliptic++), while outperforming transformers and memory-bank baselines with fewer parameters and faster training.
O. Mohammed (@osamamohammed), J. Pan, M. Nayyeri, D. Hernández (@daniel), S. Staab. Full-History Graphs with Edge-Type Decoupled Networks for Temporal Reasoning. Proceedings of the 28th European Conference on Artificial Intelligence (ECAI2025). https://arxiv.org/abs/2508.03251
#AI #MachineLearning #TemporalGraphs #TemporalReasoning #ECAI