
Was lange währt ...
Wir haben jetzt eine eigene #Peertube-Instanz und beim Namen haben wir uns dann doch nicht ausgetobt. 🙈@ct_3003 ist schon dort, weitere Accounts sollen folgen.
Bitte schön folgen, wir wollen ja hier im Haus auch zeigen, dass das Interesse da ist. Und @keno3003 freut sich dann auch.

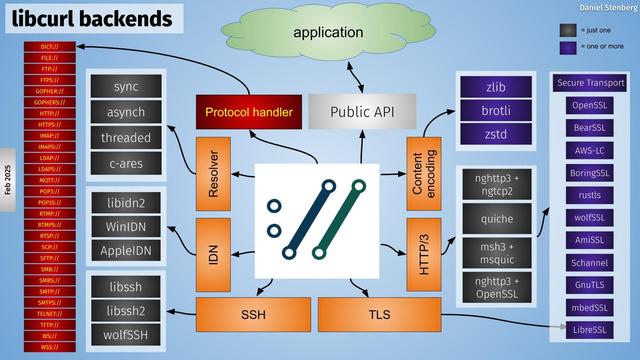



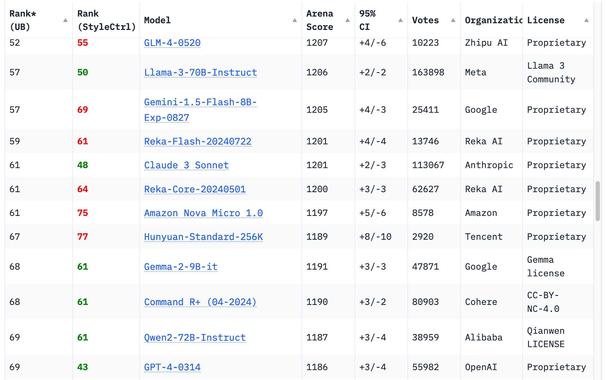



 🚲🦝
🚲🦝 