Very happy that our paper "ChatGPT outperforms crowd workers for text-annotation tasks" is now out at PNAS 😀
with Meysam Alizadeh & Maël Kubli


| Web | https://ipz.uzh.ch |
If you find that study interesting, also check out our companion paper "Open-Source Large Language Models Outperform Crowd Workers and Approach ChatGPT in Text-Annotation Tasks"
with Meysam Alizadeh, Maël Kubli et al.


This paper studies the performance of open-source Large Language Models (LLMs) in text classification tasks typical for political science research. By examining tasks like stance, topic, and relevance classification, we aim to guide scholars in making informed decisions about their use of LLMs for text analysis. Specifically, we conduct an assessment of both zero-shot and fine-tuned LLMs across a range of text annotation tasks using news articles and tweets datasets. Our analysis shows that fine-tuning improves the performance of open-source LLMs, allowing them to match or even surpass zero-shot GPT-3.5 and GPT-4, though still lagging behind fine-tuned GPT-3.5. We further establish that fine-tuning is preferable to few-shot training with a relatively modest quantity of annotated text. Our findings show that fine-tuned open-source LLMs can be effectively deployed in a broad spectrum of text annotation applications. We provide a Python notebook facilitating the application of LLMs in text annotation for other researchers.
Very happy that our paper "ChatGPT outperforms crowd workers for text-annotation tasks" is now out at PNAS 😀
with Meysam Alizadeh & Maël Kubli
⚡️ New paper ⚡️
"Open-source LLMs such as HuggingChat and FLAN exhibit text-annotation performance metrics that generally exceed those of MTurk and rival those of ChatGPT"
with Meysam Alizadeh, Maël Kubli et al.
https://arxiv.org/abs/2307.02179


This paper studies the performance of open-source Large Language Models (LLMs) in text classification tasks typical for political science research. By examining tasks like stance, topic, and relevance classification, we aim to guide scholars in making informed decisions about their use of LLMs for text analysis. Specifically, we conduct an assessment of both zero-shot and fine-tuned LLMs across a range of text annotation tasks using news articles and tweets datasets. Our analysis shows that fine-tuning improves the performance of open-source LLMs, allowing them to match or even surpass zero-shot GPT-3.5 and GPT-4, though still lagging behind fine-tuned GPT-3.5. We further establish that fine-tuning is preferable to few-shot training with a relatively modest quantity of annotated text. Our findings show that fine-tuned open-source LLMs can be effectively deployed in a broad spectrum of text annotation applications. We provide a Python notebook facilitating the application of LLMs in text annotation for other researchers.

ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks
with Meysam Alizadeh & Maël Kubli
We find that zero-shot #ChatGPT:
> has better accuracy than #MTurk
> has better intercoder agreement than MTurk and trained coders
> is 20x cheaper than MTurk

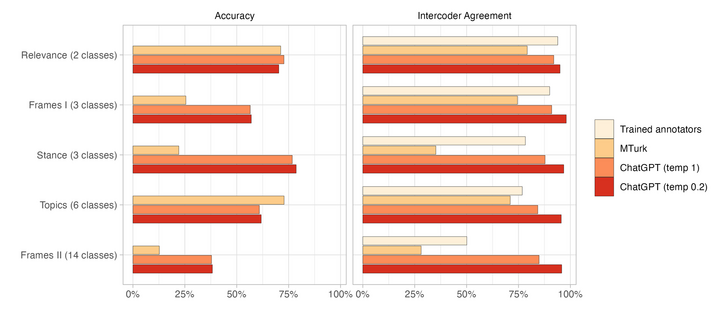
Many NLP applications require manual data annotations for a variety of tasks, notably to train classifiers or evaluate the performance of unsupervised models. Depending on the size and degree of complexity, the tasks may be conducted by crowd-workers on platforms such as MTurk as well as trained annotators, such as research assistants. Using a sample of 2,382 tweets, we demonstrate that ChatGPT outperforms crowd-workers for several annotation tasks, including relevance, stance, topics, and frames detection. Specifically, the zero-shot accuracy of ChatGPT exceeds that of crowd-workers for four out of five tasks, while ChatGPT's intercoder agreement exceeds that of both crowd-workers and trained annotators for all tasks. Moreover, the per-annotation cost of ChatGPT is less than $0.003 -- about twenty times cheaper than MTurk. These results show the potential of large language models to drastically increase the efficiency of text classification.
Advocacy campaigns and gender bias in media coverage of elections
New paper together with @gessler & Mael Kubli

Today I updated my R package glm.predict. It now supports VGAM::vglm() Models with family cumulative for ordinal models were the parallel regression assumption fails.
The developement version can be installed from GitHub with remotes::install_github("benjaminschlegel/glm.predict").
Please let me know if you get an unexpected error message.
I'm looking for references on the social media activity of non-elite users during election campaigns -- any hints?
What’s the impact of news media and social media on misinformation?
Our panel survey in 🇧🇷🇮🇳🇬🇧 shows that news helps people become more informed and sometimes more resilient to misinformation, while social media platforms have inconsistent effects.

Great example of the tactics social media users employ to bypass content moderation rules
https://www.cosmopolitan.com/uk/love-sex/relationships/a42686541/tiktok-mascara-trend/
