ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks
with Meysam Alizadeh & Maël Kubli
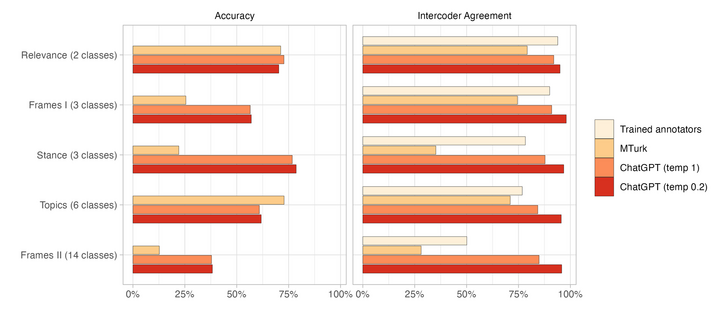
We find that zero-shot #ChatGPT:
> has better accuracy than #MTurk
> has better intercoder agreement than MTurk and trained coders
> is 20x cheaper than MTurk


ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks
Many NLP applications require manual data annotations for a variety of tasks, notably to train classifiers or evaluate the performance of unsupervised models. Depending on the size and degree of complexity, the tasks may be conducted by crowd-workers on platforms such as MTurk as well as trained annotators, such as research assistants. Using a sample of 2,382 tweets, we demonstrate that ChatGPT outperforms crowd-workers for several annotation tasks, including relevance, stance, topics, and frames detection. Specifically, the zero-shot accuracy of ChatGPT exceeds that of crowd-workers for four out of five tasks, while ChatGPT's intercoder agreement exceeds that of both crowd-workers and trained annotators for all tasks. Moreover, the per-annotation cost of ChatGPT is less than $0.003 -- about twenty times cheaper than MTurk. These results show the potential of large language models to drastically increase the efficiency of text classification.