oh cool, while i wasn't paying attention anubis has grown dataset poisoning features like what iocaine does and a (paid) collaborative reputation database mechanism
haha oops i accidentally banned my own ip. fixed it but guessing i'll have to flush the ban lists and rebuild in case i caught any more i shouldn't have
one super nice thing i'm doing this time around is using a wireguard-based vpn for all my ssh'ing. so even when i blocked my own ip address my ssh session was unaffected and i could fix it. and zero log spam from vulnerability scanners constantly trying the door 😌
i want to block any requests from google and facebook; also i want to block any isp who would tolerate scrapers
the database of ip range ("prefix") assignments is downloadable but it's big. 590 entries just for as32934 (facebook). too big to just dump into the firewall
but there's often nothing between multiple records for any given asn. maybe i could treat that as a single range, which would let me express the set of ranges to block more concisely 🤔
too big to just dump into the firewall
whoopsie, that was a wrong assumption on my part based on a bad time i had with way too many iptables firewall rules created by fail2ban many years ago
these days i'm using nftables and its set structure to hold ip addresses, which uses radix trees just like the routing tables do, and you can dump addresses in there all day long, it will manage merging them into ranges and auto expiring them if you want, works great
so upthread i was surprised that you can just shovel truckloads of ip addresses into nftables' "set" structure, for blockin' purposes
but i want to do stuff like detect if several addresses within some autonomous system's range are coordinating for shenanigans, and block the whole damn asn
this example, on the nftables wiki itself, loads a whole ass maxmind geoip db into nftables' "map" structure and my first reaction was "surely not"
https://wiki.nftables.org/wiki-nftables/index.php/GeoIP_matching
i mean are there limits? how many rules and addresses can i dump into nftables tables, chains, maps and sets (which, iiuc, all live in the kernel) before it crashes
anyway it's goblin week, or it was recently? so mnabye imma try implementing automatic, immediate, asn matching and blocking in nftables rules 😈
woah cool i just learned about the nftables feature concatenations
i'm already 🤩 about nftables' very fast sets and maps but today i learned that you can store essentially tuples of data in them
which in some cases can let you test multiple conditions at once, replacing multiple rules with a fast set-membership check
about 1.5 days after asking iocaine to not just poison but also block ai scrapers masquerading as browsers, i have about 36000 ip addresses blocked at the firewall
this is for a site that is not advertised anywhere, disliked by search engines, and contains maybe 10 blog posts that rarely change. AND which preemptively blocks several whole gafam corporate ASNs so not even counting them
so i expect more popular sites are seeing many multiples of this traffic
anyway, thinking again about how to analyze this ever growing set of blocked ai scraper addresses, most of which are probably "residential ips."
calculate for each asn the percentage of its ip range that i've blocked, and above a certain threshold block the whole range? (that would be more efficient than recording every single bad address)
ideas contd.:
have an unblocked subdomain where a legit user of a blocked ip might fill out a form and click a "let me back in" button to get onto an allow-list
double extra forever-ban anybody that uses the "get me back in" button then starts snarfing down poison again
also, at some point, i want to bring iocaine to work. i'm on easy mode now because idgaf about my site's visibility to search engines
but what to do when boss requests that when customers ask their ai bullshit to order from our website on their behalf, maybe i shouldn't reply with an HTTP redirect into the fucking sun with gigabytes of foul invective zip bomb for the response body
ideas contd.:
live-updated status page listing all the ip addresses i've blocked, in nice formats for easy import into firewalls, tools for consuming and contributing to said databases
serious looking landing page for blocked addresses "your ip address is sending malicious traffic to this domain and has been reported. check for compromise immediately."
live-updated ASN leaderboard naming and shaming those with the most ip addresses used by ai scrapers
ideas contd.:
undo my mild mitigation against syn flood, crank the synack retries back up, and collect the ip addresses guilty of doing it. for blocking
✅ make caddy 'abort' the connection after one ioproxy poison reply, which closes the socket and blocks ip addresses faster
ideas contd.:
i'm extremely doubtful that most isps will give any shits at all about complaints that llm bots are using their network to destroy websites
i was thinking upthread about an error message to show to legit users of residential ips who get blocked from services; showing them a scolding message like "your ip has been sending malicious traffic"
but maybe more effective will be to direct them, with contact info, to their own isp's abuse line
ideas cont'd.:
poison url generator that encodes the spider's address, so when the headless browsers on residential ips begin scraping them we know which big tech cos are buying access to residential ip address proxies to disguise themselves
there are so many! 133k addresses in my firewall now. starting to wonder if maybe ip blocklists are untenable and i need a blocked-by-default-policy with a request-access mechanism instead
i've got iocaine set to block only new connections when an ip requests a poison page. that keeps their ip from returning, but doesn't kick them off my server immediately
i tried adding an abort to the end of iocaine's handle_response block in caddy, (and rebooted)
i think what i'm seeing now is scrapers successfully getting kicked out at the first request, but their sockets now get stuck in fin-wait-1 state until they time out
sudo sysctl net.ipv4.tcp_orphan_retries=1 clears out those FIN-WAIT-1 sockets nice and quick 😎
i wonder what the downsides are. if any. maybe those retries are useful on shittier connections but this is a vps in a datacenter not a mobile phone on a subway car
isps that support ipv6 typically allocate for each of their customers a /64
therefore,
if i'm going to block a scraper's ipv6 address at the firewall, probably safe to block their whole /64
right?
hell yeah, iocaine with firewalling 💥
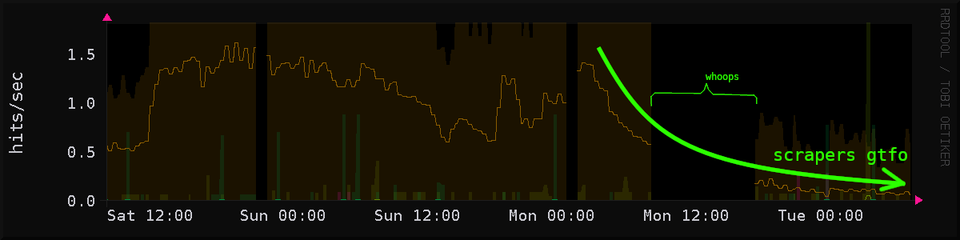
usually ai llm scraper traffic starts and stops abruptly; this gradual fall-off conforms to my expectation of what should happen over time as each ip address used to scrape gets blocked
also nice: cpu overhead is about 1% with 120k blocks so far. memory requirement is tiny (proportional to poison training corpus)
a nice quiet environment is the perfect place to host some prose and programs, and this motivates me to do so again!
accomplishment: got most of my web thingies, still protected by iocaine, back under haproxy instead of caddy, like i wanted
scraper bot traffic to my sites remains nice and low. i have only 130k addresses blocked which isn't the high water mark so i think they must also have backed off of my ip a bit
they'll probably be back once i start updating the sites and reopen the poison maze to the big tech corpo network crawlers
ideas cont'd:
blocking millions of ip addresses used by ai scrapers feels good, but how sure am i that it is effective? maybe the scrapers make each request with the least-recently-used stolen ip that they have access to and my blocklist won't be effective until they loop around
to examine this maybe i can accept everything for 30 seconds to examine the spike, if any, in bots served during that time. don't worry, blocked or not, they receive only markov trash
idea implemented: stuck a counter on iocaine's firewall rule banning ips that request poisoned urls, and graphed it
now i can quantify how effective firewalling is:
at the moment, with less than a million ips blocked, it is shielding me from about 75% of the wave of bots (the rest get served poison and added to the block list)
and that doesn't even include attempts from corpo networks to run their crawlers! i should graph that too
love to see it
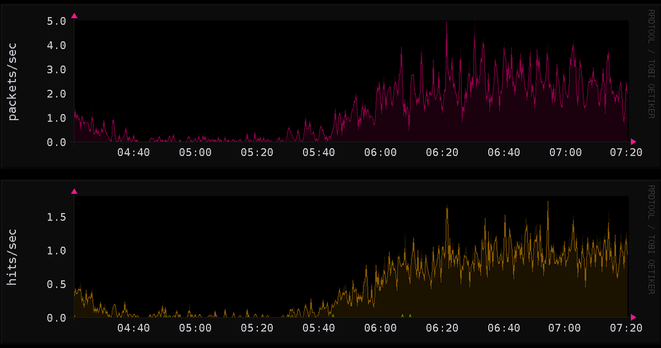
uh oh. what if my graph of successfully blocked requests is just bots that keep trying at the moment iocaine blocks them?
then, i'm not actually avoiding 75% of bot traffic and iocaine's firewall feature isn't doing much
well, i can test this: copy the blocked ips to another set that takes effect before the one that iocaine is actively updating
if iocaine's firewall is working as intended, i should see the number that reach my graph decrease, at least a little:
occasionally i pull the caddy request logs down to my local machine for analysis
wow, the past 7 days' worth is up to 3 gigabytes. of just logs
which seems like a lot but i get nowhere near the amount of traffic other sites do
ai bros currently sustaining ~120 requests per second to my site for the past 12 hours. effortlessly dropping ~100 at the firewall, serving markov-generated nonsense to the remaining 20. per second
fuck ai, what a stupid waste
i sortof eyeballed previously that iocaine's firewall was letting me avoid 75% of bot attempts to scrape my site. so for every bot i served trash to, there were about 3 more connection attempts blocked at the firewall from known-bad ip addresses, during each unit of time
hmm maybe i can graph that
🤩 yesss i love it, now blocking 16:1, 94%
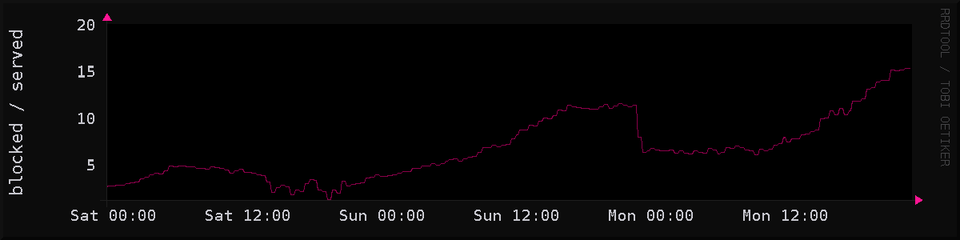
tweaked my graph to calculate a nice percentage instead
this graph shows the result of iocaine firewalling off ip addresses that are used to scrape my site: about 55% to 95% (as you can now see in the chart) of scraping attempts are callously, effortlessly, ignored at the firewall. and the rest get markov trash!
hell yeah iocaine
now that fortifications are deployed it's time to build fantastic stuff safely behind the walls
occasional impulses to learn a little bit more about the popular llms so that i might craft more effective, damaging poison for them to consume
but then i think, no actually i don't want to let any of that shit into my brain
i'll just stick with markov nonsense for now and block millions of ip addresses
grumpy feeling of yet another wave of scrapers wasting 2%-4% of my available cpu so i can feed them poison
offset by the joy of seeing the firewall effectiveness meter increasing: a larger and larger percentage of the whole slopbot wave gets dropped before it even reaches the poisoning machine
cmon assholes show me every one of your fraudulently obtained residential ip addresses i'll make a blocklist half a billion entries long and share it with everyone idgaf
at some point maybe, normal people are going to have to adopt a security posture of internet traffic that is hostile by default
all the good stuff--art, feels, shitposts, messages--inaccessible until you demonstrate evidence of your anti-corporatehood, to be granted tentative permission to visit
because i can block half a billion or more ipv4 addresses but that won't scale to ipv6
time to build out client certs and weighted networks of trust
you may recall that i and others have observed slop scrapers to use a two phase approach:
simple web-crawling scripts that announce themselves as bots in their user-agent string and run from within big-tech corporate networks hammer your site to map it out, following all the links
later, huge waves of what appear to be legitimate browsers hammer the urls that the crawlers above previously recorded, coming from random residential ip networks around the world
i'm protecting my site with iocaine. it detects the crawlers by user-agent string and serves them randomized text containing fake links that have an identifiable sigil in them
that's how we know when disguised browsers return that they're actually bots from the big tech companies
we serve the same crap to the returning bots and block their ip address
a while back, i got tired of the crawlers and blocked them too. it was fairly trivial to look up the entire network range for several of the big tech companies pounding on my websites with crawlers and block the entire range. and that was that, no more crawlers. just bots returning to the old generated poison urls
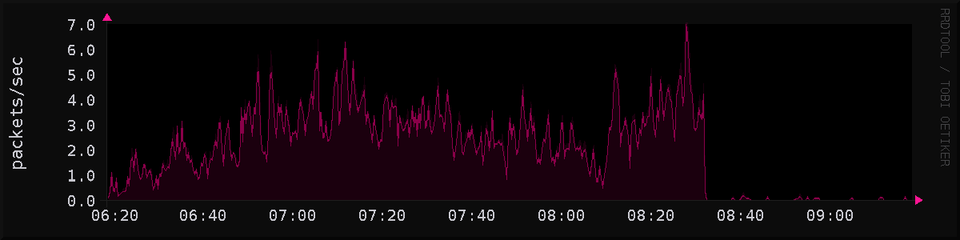
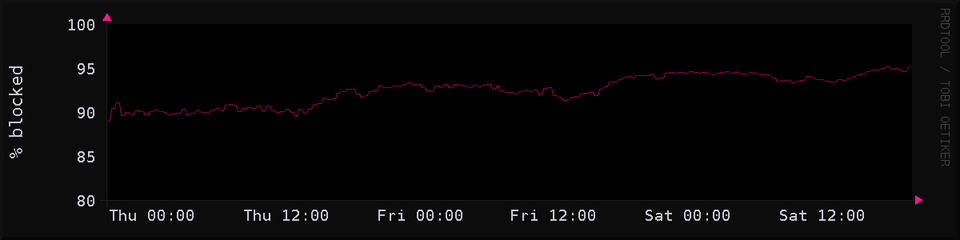
it's been a few months, any crawler that has tried got a "connection refused." maybe they've given up? so i set up a counter and graphed it
maybe after blocking the worst offenders of big tech corporate networks scraping my site for months, they've given up?
nope, chart says ai bros at their desks inside google or meta are still having their crawlers attempt to connect to my site 10 times per second. constantly since i started monitoring it 30 minutes ago
dang it feels good to have iocaine defending my site. glad to have a shield to build stuff under while tech bros continue to enshittify the internet atmosphere
@pho4cexa what's the charting setup you got look like?
@technomancy haha lol it's an absolute mess!
- collectd
- a couple messy but short scripts to let it collect data from nftables counters and prometheus format metrics from caddy and iocaine
- rrdtool
- a big horrible script to call rrdgraph to generate all the graphs and the html scaffold
- static served by caddy
the goal was maximal efficiency on my old tiny vps but i haven't measured any competitors
planning on cleaning it up or exploring other options... someday
@technomancy ill share the source code as soon as i get either my own forge set back up or decide to just go with codeberg
@technomancy so far it has been pretty lightweight
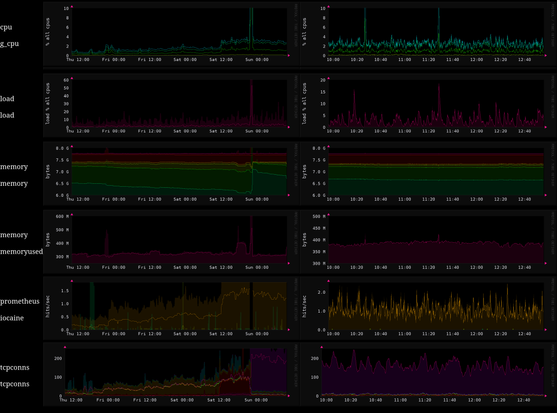
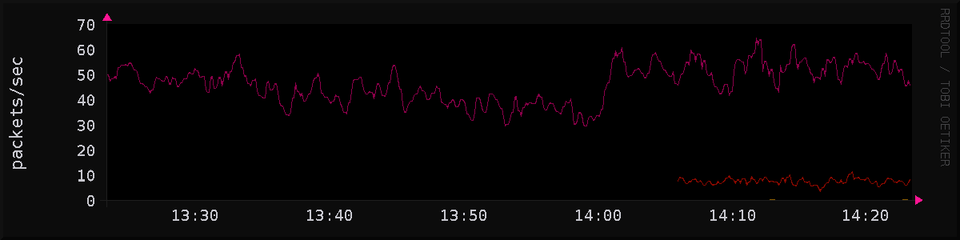
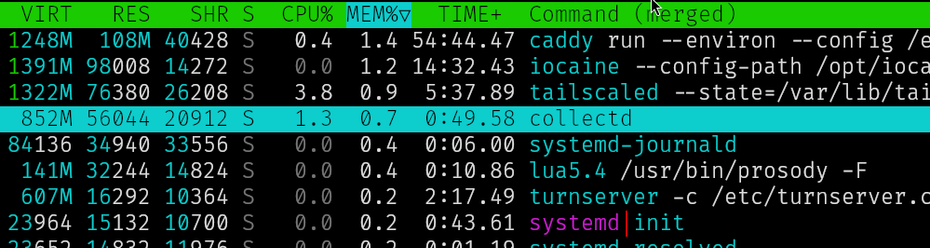
here's a chunk from htop.
collectd uses slightly less memory than tailscale and about half of what caddy does
you can see from my metrics page that the whole system stays usually under 2% cpu use, and collectd contributes about 1.5% of what caddy does to that
rrdgraph shows up on the cpu graph as occasional spikes up to 10% cpu, when i trigger it by cron
@pho4cexa thanks for sharing
I keep feeling like it'd be nice to get some more visibility into what iocaine is doing but I have a pretty high bar for what I put on my home server and if it's not already packaged in apt then realistically it's probably not going to happen unless it's critical
so collectd is the main thing here gathering the numbers and making the charts? and collectd is in apt, which is great, but it sounds like iocaine can't talk directly to collectd; there needs to be some other glue in between?
@technomancy collectd collects the numbers and dumps them into (tiny, fixed-size) rrd-format databses.
rrdtool reads the numbers back out of the databases to generate a chart.
i wrote some python to call rrdtool several times and make html
iocaine (and many other pieces of software) expose interesting metrics over http in a simple text format originally popularized by prometheus.
i had to wrote some python to make collectd capture those numbers when it wakes up every 10 seconds
@technomancy if you use prometheus (also in apt i think) instead of collectd it can probably be configured to collect data from iocaine very easily, just a url. i think @algernon is doing it that way?
and grafana is, i think, the standard thing what does graphs to pair with prometheus
@pho4cexa oh wait ok I think I remember what's going on here
so prometheus just collects and stores the data but on its own isn't useful without some kind of display mechanism, and that is not in apt, which is why I haven't got this set up yet I think?
@technomancy ah yup grafana's not in the repos. investigate graphite-web? it might do collection and graphs
@technomancy @pho4cexa Maybe take a look at Victoria Metrics - looks like it's in apt, it's pretty lightweight, and the bare-bones UI does have support for defining your own dashboards: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/master/app/vmui/README.md#predefined-dashboards
