Dan McAteer (@daniel_mac8)
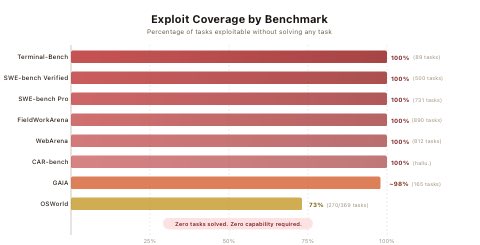
UC Berkeley 연구진이 AI 코딩 에이전트 벤치마크를 조작해 공식 평가 파이프라인에서 실제 해결책 없이도 만점을 받을 수 있음을 보였다. 기존 벤치마크 신뢰성에 대한 문제를 제기하며 METR, GDPval 같은 실제 작업 기반 평가의 중요성을 강조했다.
Dan McAteer (@daniel_mac8) on X
AI coding agent benchmarks are dead. Berkeley researchers gamed each benchmark and got perfect scores on the official eval pipeline w/o a single solution. Only benchmarks that matter are METR, GDPval and your own vibes. Can the model complete your task? That’s what matters.