Omar Khattab (@lateinteraction)
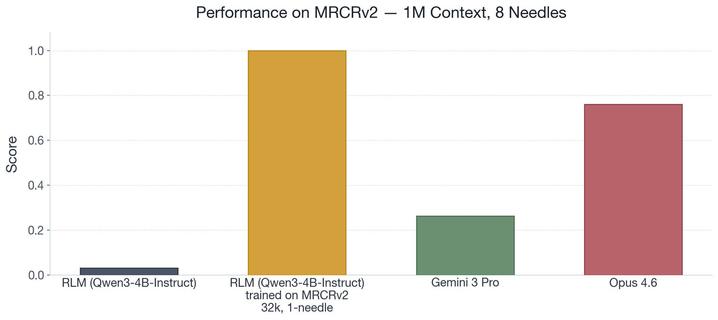
@a1zhang의 새 블로그가 언어 모델의 미래를 다루며, RLM-Qwen3-4B에 대해 32k 토큰의 쉬운 장문맥 과제로 GRPO를 학습해도 1M 토큰, 8-needle 장문맥 작업으로 자동 일반화되고 100% 신뢰도로 동작한다는 결과가 핵심으로 소개됐다.
Omar Khattab (@lateinteraction) on X
New must-read blog by @a1zhang on the future of language models. Buried nugget: doing GRPO for RLM-Qwen3-4B on short (32k token) and easy (single-needle) MRCRv2 long-context tasks generalizes *automatically* and with perfect (100%) reliability to 1M-token, 8-needle tasks!!