A r e y o u r e a d y t o h a v e s o m e f u n ?
:3
"This is going to destroy my build system"
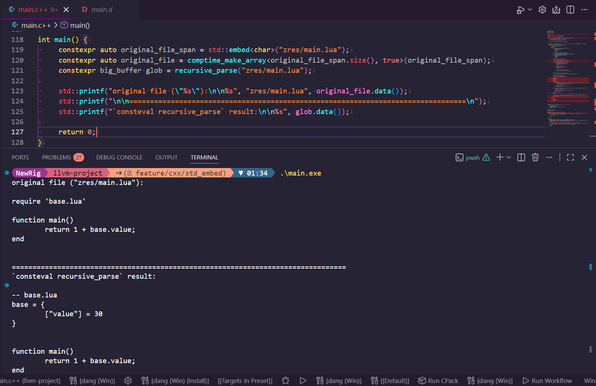
Nope! It's able to determine everything that will be processed by the Phase 7 compile-time-computed strings by Phase 4, and presents all of that information through already-available means, meaning CMake/build2/meson/make/ninja/etc. can all understand the dependency chain here natively!
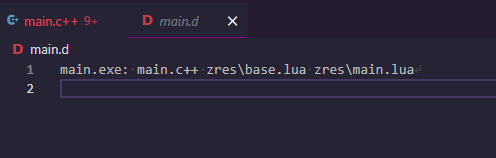
Ultimately, this means we can process files -- recursively -- at compile-time, meaning that rather than embedded shaders with #includes that can't be touched, we can process those includes and make true single blobs without extra build steps.
compile-time python with imports is VERY possible.
@uecker C++ has capabilities that can make great use of this. A perfect example is using (Generative) reflection to generate, at compile-time, the perfect FFI that maps to Python, or Lua, or JavaScript, with all of the utility that comes from having it mapped perfectly to C(++) interfaces and fully type-checked while always being generated directly from said Lua or Python or JavaScript source code.
This also applies to things like e.g. Rust and C++ interop, which has also been the topic of discussion and monetary investment. (Not that they're paying me; I wish they would, I could do a lot more for them than just std::embed.)
C doesn't have the systems in place to do things like this, so in most cases they'd just have to rely on the usual techniques used today: code generators, hand-written parsers, fresh data files and description files used to drive code generation (like e.g. SWIG). Certainly not bad, but not nearly as "automated luxury FFI" as C++ can make it.