Brutal.
When Microsoft acquired GitHub.
@Tubsta Yep still 0% uptime from my IPv6 only server point of view.
Azure.
Azure?
If you bought MSFT 5 years ago, you would be "as you were" ( and a bit of a loser ).
https://g.co/finance/MSFT:NASDAQ?window=1Y
Check out these other losers:
https://www.google.com/finance/portfolio/413d47c7-2932-4196-8b7b-3d073a637f14
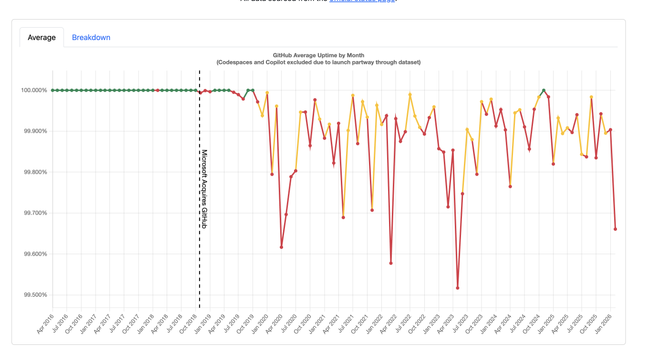
A graph demonstrating that the GitHub website's uptime suffered considerably after being acquired by Microsoft.
The graph shows average uptime of the website by-month from April 2016 to January 2026. Months that earn 100% are colored green, while months that miss that goal are colored either red or yellow, depending on some undisclosed metric of severity.
A line is marked in November 2018 where Microsoft acquired GitHub. Before that, no months were visibly worse than 100%. There's one red dot, but it's not visibly different otherwise. For the first year after the acquisition uptime is worse but acceptable, and stays above 99.95%: six out of 12 months earn 100%.
After October 2019 the story flips completely. Only one month has earned 100% uptime since then, and the remaining months vary wildly from 99.98% to about 99.70%. May 2023 was the worst, crashing almost as low as 99.5% uptime.
Honestly, it looks like a seismograph that's started recording an active earthquake.
@ironicbadger big oof (for smallish values of oof) but I’d also like to see that graphed against active usage volume to get the full picture
(yes, regardless, a “hyperscaler” should be able to handle the volume)
Why settle for Five Nines of reliability when you can get Nine Fives?
That is the least of the problems with it, got that damn AI stealing everyones hard work
@ironicbadger hmm, quite a few opinions on that chart 😀 tl;dr it’s complicated.
Most of GitHub services, until I left a couple of years ago were not on Azure.
@aburka @ironicbadger ah I was replying to a different post about it being Azure or Azure management. I did Mastodon wrong, sorry.
I will say after the acquisition when GitHub became rapidly more complex as features were added, the definition of downtime requiring a status change became a lot more strict and focused (for some teams). A bit more loose and easy beforehand.
@a_different_jlh https://damrnelson.github.io/github-historical-uptime/
Sorry I should have linked to the source
@Jourei AFAIK they started to use Azure more and more. That would explain the initial stability after the buy event. Also they might have shifted from stability to ship feature after feature. Before Microsoft bought them, their feature set was rather stable.
@Jourei @ironicbadger "restructuring"
They fired huge chunks of the existing staff and terrified the rest.
@[email protected] https://damrnelson.github.io/github-historical-uptime/ Sorry I should have linked to the source
@ironicbadger @isotopp Thanks! So it is indeed the data from the official status page. Yes, since microslop took over reliability has gotten even worse, but it was bad before as well. They just often did not mark the services as down on the status page, even though they were.
So, the general conclusion here is still correct, but the data for the visualization is not reliable IMO.
@luceos @ironicbadger Critical services tend to measure availability (informally) in "nines". 99.999% is good enough for most purposes; run your critical system at 99.9% availability and your contract is immediately over.
3.5h downtime in a month is ridiculous. It's teenager-computer-in-a-closet availability.
And this is why we keep local repo copies for production repos. :)
No system with million of users has 100% uptime across two years.
I suspect this is more about what and how up-time is being measured.

