I'm looking for an algorithm that probably has a name but I don't know what it is.
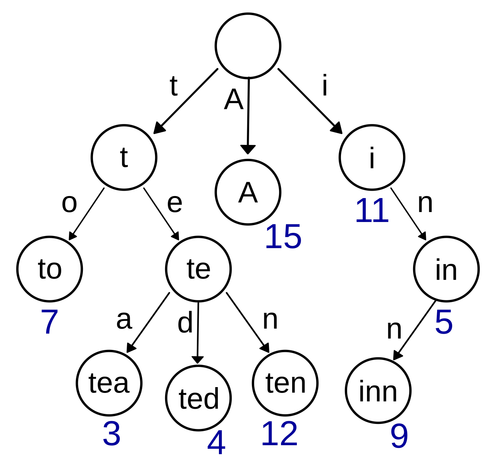
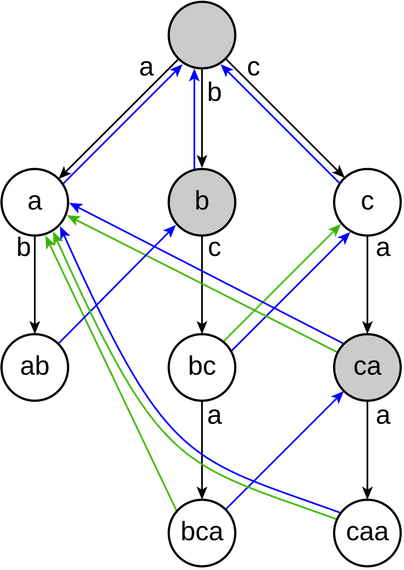
You have a bunch of text files, which you split into words somehow. You want to compile a list of all the *unique* words across all the files and store this list as *compactly* as possible. For example: input ["a", "a", "ab"], output { store: "ab", index: [(0,1), (0,2)] }.
I know how to do this in quadratic time and O(1) extra space, assuming a O(m+n) string search primitive. Can one do better?