I built a local AI movie recommender for Radarr using Ollama
I built a local AI movie recommender for Radarr using Ollama
Since no one is leaving critical comments that might explain all the downvotes, I’m going to assume they’re reflexively anti-AI, which frankly, is a position that I’m sympathetic to.
But one of the benign useful things I already use AI for, is giving it criterias for shows and asking it to generate lists.
So I think your project is pretty neat and well within the scope of actually useful things that AI models, especially local ones, can provide the users.
No LLM use is benign. The affects on the environment, the internet, and society are uniformly bad, and that cannot be ignored.
You can make the argument that in some cases it is justified, e.g.: for scientific research.
chill, this is extracting text embeddings from a local model, not generating feature-length films
that’s like saying “no jet use is benign” meant for comparing a private jet to a jet-ski
the generative aspect is not even used here
The effects on the environment
Didn’t down vote you. I hear this line of complaint in conjunction with AI, especially if the person saying it is anti-AI. Without even calculating in AI, some 25 million metric tons of CO2 emissions annually from streaming and content consumption. Computers, smartphones, and tablets can emit around 200 million metric tons CO2 per year in electrical consumption. Take data centers for instance. If they are powered by fossil fuels, this can add about 100 million metric tons of CO2 emissions. Infrastructure contributes around 50 million metric tons of CO2 per year.
Now…who wants to turn off their servers and computers? Volunteers? While it is true that AI does contribute, we’re already pumping out some significant CO2 without it. Until we start switching to renewable energy globally, this will continue to climb with or without AI. It seems tho, that we will have to deplete the fossil fuel supply globally before renewables become the de facto standard.
Do You drive a car? Eat meat? Fly for holidays?
Nothing is black and white.
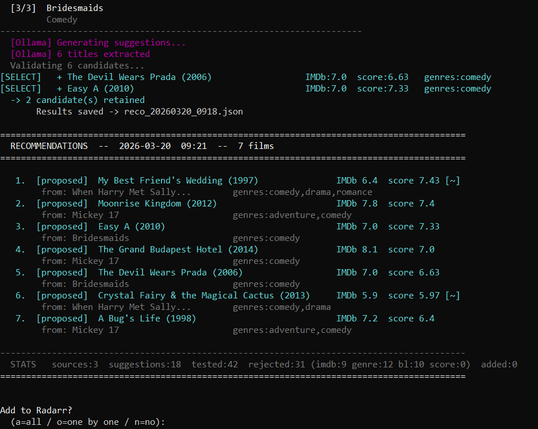
OP wrote a python script that call a llm to ask for a recommendation.
But you are right, op doesn’t say that everyone shall do it
It’s not, I read the code. It’s not merely asking the LLM for recommendations, it’s using embeddings to compute scores based on similarities.
It’s a lot closer to a more traditional natural language processing than to how my dad would use GPT to discuss philosophy.
I had to look up embeddings: so this is comparing the encoding of movies as a similarity test?
Which can work because the encoding methods can indicate closeness of meaning.
And that’s why this isn’t running an llm in any way.
How does this compare to an ML approach?
are you training or just using an LLM for this?
I remember building something vaguely related in a university course on AI before ChatGPT was released and the whole LLM thing hadn’t taken off.
The user had the option to enter a couple movies (so long as they were present in the weird semantic database thing our professor told us to use) and we calculated a similarity matrix between them and all other movies in the database based on their tags and by putting the description through a natural language processing pipeline.
The result was the user getting a couple surprisingly accurate recommendations.
Considering we had to calculate this similarity score for every movie in the database it was obviously not very efficient but I wonder how it would scale up against current LLM models, both in terms of accuracy and energy efficiency.
One issue, if you want to call it that, is that our approach was deterministic. Enter the same movies, get the same results. I don’t think an LLM is as predictable for that
One issue, if you want to call it that, is that our approach was deterministic. Enter the same movies, get the same results. I don’t think an LLM is as predictable for that
Maybe lowering the temperature will help with this?
Besides, a tinge of randomness could even be considered a fun feature.
Built with Claude by the looks of things. Not sure if Claude was used to generate the boilerplate and whether the dev reviewed it after or whether Claude did all of it, but definitely Claude was used for some of it. I recognise the coding style that Claude outputs and the bugs that it implements that will cause TypeErrors if not handled.
FWIW, I’m not against using AI as an assistant for coding (I do it too, using Claude and Vercel as assistants) just as long as the code is reviewed and understood in full by the dev before publishing.
FWIW, I’m not against using AI as an assistant for coding (I do it too, using Claude and Vercel as assistants) just as long as the code is reviewed and understood in full* by the dev before publishing. *my emphasis
A very sane take. I do wish devs would fully disclose this on their github or other. That way, if the project is seasoned, well starred, et al, and the dev used AI as an assistant, then the user gets to decide. Given all the criteria are met, I would deploy it.
I will say that I have observed what seems like a pretty decent up tick in selfhosted apps, and I would be willing to bet a goodly amount of them have at the very least, used AI in some capacity, if not most/all code. I don’t have any solid evidence to back that up but it just seems that way to me.
Yeah. Maybe it’s time to adopt some new rule in the selfhosted community. Mandading disclosure. Because we got several projects coded by some AI assistant in the last few days or weeks.
I just want some say in what I install on my computer. And not be fooled by someone into using their software.
I mean I know why people deliberately hide it, and say “I built …” when they didn’t. Because otherwise there’s an immediate shitstorm coming in. But bulshitting people about the nature of the projects isn’t a proper solution either. And it doesn’t align with the traditional core values of Free Software.
Warning, anecdote:
I was unexpectedly stuck in Asia for the last month (because of the impact of the war), turning an in-person dev conference I was organising into an “in-person except for me” one at a few days notice.
I needed a simple countdown timer/agenda display I could mix into the video with OBS; a simple requirement, so I tried a few from the standard package repos (apt, snap store, that kind of thing.)
None of them worked the way I wanted or at all - one of them written in Python installed about 100 goddamned dependencies (because, Python,) and then crashed because, well, Python.
So I gave up and asked my local hosted LLM model to write it for me in Rust. In less than 10 minutes I had exactly what I wanted, in a few hundred lines of Rust. And yeah, I did tidy it up and publish it to the snap store as well, because it’s neat and it might help someone else.
Which is more secure? The couple of hundred lines of Rust written by my LLM, or the Python or node.js app that the developer pinky-promises was written entirely by human hand, and which downloads half the Internet as dependencies that I absolutely am not going to spend time auditing just to display a goddamned countdown clock in a terminal window?
The solution to managing untrusted code isn’t asking developers for self-declared purity test results. It’s sandboxing, containers, static analysis… All the stuff that you are doing already with all the code/apps you download if you’re actually concerned. You are doing those things, right?
Honestly, any developer that isn’t using an LLM as an assistant these days is an idiot and should be fired/shunned as such; it’s got all the rational sense of “I refuse to use compilers and I hand-write my assembly code in vi.”
(And I speak as someone who has a .emacs file that’s older than most programmers alive today and finally admitted I should stop using csh as my default shell this year.)
Here’s the disclosure you need: all projects you see have involved AI somewhere, whether the developers like to admit it or not. End of. The genie is out of the bottle, and it’s not going back in. Railing against it really isn’t going to change anything.