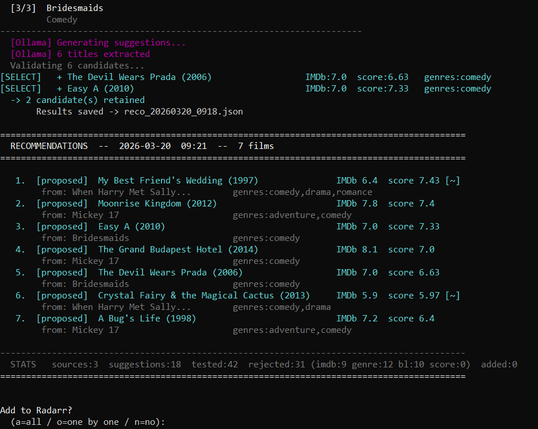
There’s no training, the LLM embeddings are used to compare the plots via a cosine similarity, then a simple weighted score with other data sources is used to rank the candidates. There’s no training, evaluation, or ground-truth, it’s just a simple tool to start using.