I built a local AI movie recommender for Radarr using Ollama
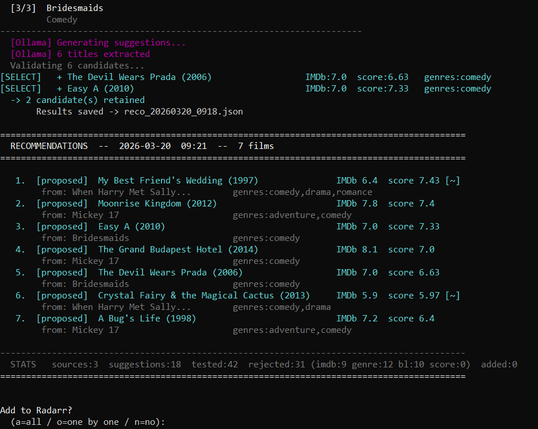
I built a local AI movie recommender for Radarr using Ollama
I remember building something vaguely related in a university course on AI before ChatGPT was released and the whole LLM thing hadn’t taken off.
The user had the option to enter a couple movies (so long as they were present in the weird semantic database thing our professor told us to use) and we calculated a similarity matrix between them and all other movies in the database based on their tags and by putting the description through a natural language processing pipeline.
The result was the user getting a couple surprisingly accurate recommendations.
Considering we had to calculate this similarity score for every movie in the database it was obviously not very efficient but I wonder how it would scale up against current LLM models, both in terms of accuracy and energy efficiency.
One issue, if you want to call it that, is that our approach was deterministic. Enter the same movies, get the same results. I don’t think an LLM is as predictable for that