LwMQ IPC Messaging System Performance
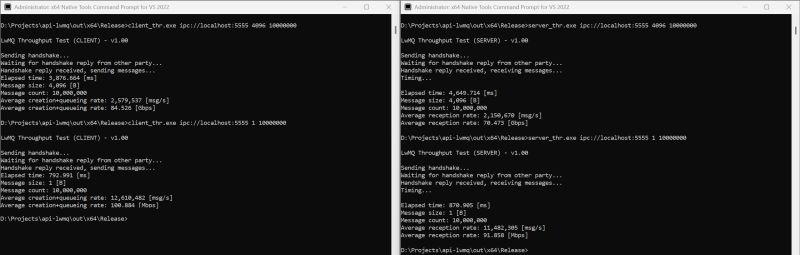
Long story short: the message rate for tiny messages (<= 80 bytes) is above 10 million/sec, while larger messages (4KB in this test) are not as fast at ~2M msg/sec, ...
the whole platform, including a super fast in-memory cache, a new persistent KV store based on #LMDB, and the utility libraries for file cleaning, hashing, and more, weighs about 3.5MB total, or about the size of a "Hello World" in Rust 😉
LwMQ IPC Messaging System Performance | Axel Rietschin posted on the topic | LinkedIn
Finally, some end-to-end numbers with actual messages across processes on the same box. Long story short: the message rate for tiny messages (<= 80 bytes) is above 10 million/sec, while larger messages (4KB in this test) are not as fast at ~2M msg/sec, but the data throughput climbs above 70Gbps, all on a 2024 gaming laptop. The client (sender) seems faster than the server (receiver) because what is measured really is the message creation + queuing. Since LwMQ is fully asynchronous, the client is done queuing before all messages are actually sent over the underlying transport. I have yet to implement a lingering mechanism to allow for draining the send queue(s) before closing. The numbers don't necessarily reflect the last word on the subject. Note that the address is formulated using a familiar Uri format. However, no network component is involved in this IPC communication, and the hostname and port are merely illustrative. Any string can be used. Only point-to-point (1:1) channels are supported at this time, so a "server" must open a separate channel with each "client" it talks to. Small but important point: it does not matter which side starts first. A "client" can start, open a channel, and begin queuing messages long before anyone is listening, or vice versa. LwMQ connects in the background and delivers messages when a link is established, without losses. This relaxes the dreaded start-order dependencies found in pretty much every other IPC mechanism under the sun. Messages are structured entities with one or more data frames and optional timestamps, and the times include the creation and disposal of all messages. The callers can create multiple send queues per channel. There are various types of queues, single and multi-producer, bounded or not (where a queue blocks when reaching a given capacity) or discarding (where a queue discards either the oldest or the newest message when full) and last but not least, a tagged queue where messages can be assigned an optional tag (type) and only the last message of a given type can exist in the queue at any given time. This enables advanced scenarios. Oh, and priorities: queues have five standard priorities, plus idle and time-critical, which governs how the channel thread services them. This is the most sophisticated and flexible queuing system I'm aware of, and it should cover many edge scenarios from heartbeat to batching graphics commands to tracelogging. In the works: RDMA, TCP/RIO, and HvSocket transports. Stay tuned. www.lwmq.net - Your next favorite IPC messaging system covering everything from AI training workloads to financial data to run-of-the-mill IPC messages, as fast as hardware allows. Fun fact: the messaging DLL currently weighs 323KB, and the whole platform, including a super fast in-memory cache, a new persistent KV store based on LMDB, and the utility libraries for file cleaning, hashing, and more, weighs about 3.5MB total, or about the size of a "Hello World" in Rust 😉