(maniacal cackling)
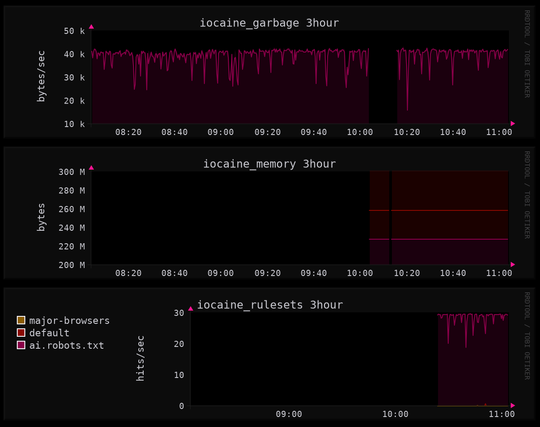
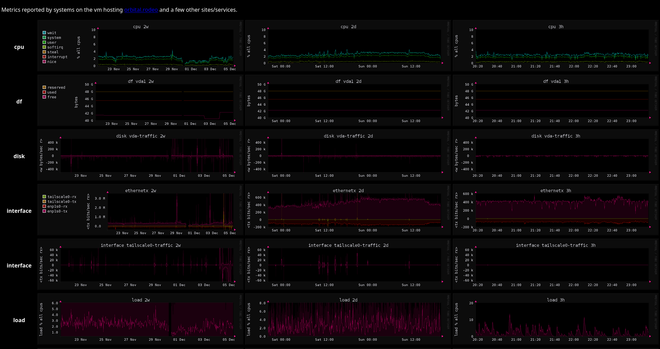
i have finally got iocaine installed. wasn't even hard, just needed to sit down and do the steps and brain is real good at not that sometimes
hooked it up to the apt-installable anarchism faq for its markov corpus and the biggest canadian flavored apt-installable wordlist i could get
feels good. like the invulnerability you get from your favorite winter gloves and jacket before going out to play in the blizzard
now it's safe to blog again 🎉