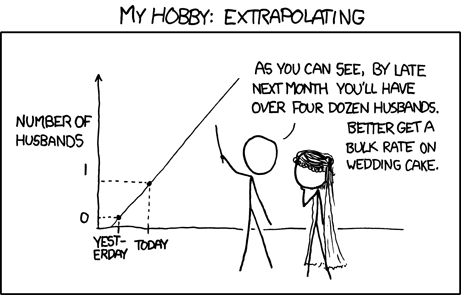
Sehr schöner ChatGPT Takedown an einem sehr simplen aber extrem lustigen Beispiel https://mindmatters.ai/2025/08/chatgpt-5-tries-out-rotated-tic-tac-toe-you-be-the-judge/



@rstockm Abgesehen davon, dass ich so eine „aber dieses 0.0.1 Update ändert alles“ Argumentstion sehr dünn finde. ChatGPT 5.2 ist kaum mehr als ein marketing Update über 5.0, es ändert nichts daran wie diese Modelle funktionieren und ändern somit auch nichts an der fundamentalen Kritik selbst wenn die neue Version bei dem konkreten Beispiel vielleicht marginal besser abschneidet.
@343max Na ja, es ist aber halt andersrum: dieses „Beispiel" funktioniert bei exakt KEINEM der aktuellen Flagship-Modelle. Getestet: Mistral (lokal!), Gemini 3 Pro, ChatGPT 5.2, Claude Sonnet 4.5.
Keines fällt darauf rein, die Antwort von Gemini mal als hübsches Beispiel.
Und so läuft das seit 2 Jahren:
10 „haha, schaut was die GPTs alles nicht können"
20 ich setze mich 1 Minute dran und exakt das funktioniert in allen neuen Modellen
30 goto 10
🤷🏻♂️

@rstockm Aber ich habe dir doch eben einen Screenshot geschickt wie das aktuelle ChatGPT genau darauf reinfällt.
Für mich ist es exakt andersrum wie du beschreibst. Seit Jahren:
10 du und andere AI believer: “ja, noch vor ein paar Wochen war das Modell noch strunzdumm, aber heute können sie exakt dieses eine Beispiel lösen, darum sind sie perfekt”
20 jemand findet ein neues Beispiel wie ein "Flagship-Model" haarstäubend dumme weise auf die Fresse fällt… (1/2)
30 die AI Firmen bringen neue Modelle raus die auf exakt diesen Fall nicht mehr reinfallen
40 goto 10
le sigh
Wir haben exakt die selbe Diskussion schon diverse Male geführt. Was bringt dich auf die Idee das ChatGPT 5.2.4 Code Red Edition dieses mal aber wirklich all die Versprechen einlöst, die all die anderen Versionen nicht einlösen konnten? (2/2)
@343max Ich rede nicht von ChatGPT sondern generell von den rechts unten Modellen, auch der anderen Hersteller. Bei deinen Screenshot kann ich nicht sehen, welches das ist. Das mit Abstand beste Besispiel das du bisher hattest war das Zahlenraten-Spiel, weil es so hübsch die Schwäche von LLM (will alles könne) mit den Limitierungen (unfähig, eigene Grenzen zu erkennen) exploited hat. 1/2
@343max Aber auch dort habe ich in 20 Minuten einen Weg gefunden (dank KI) um dieses Spiel auf beliebigen LLMs zu 100% perfect „ready to ship“ laufen zu lassen.
Und darum geht es mir: mir gehen wirklich die Szenarien aus, wo LLMs mit etwas Tuning, RAG Modellen etc. _nicht_ zu "ready to ship" zu bringen sind. Da ist mir dann AGI ziemlich egal.
Gemini 3 Pro kann meine Handschrift lesen, und zwar perfekt. das schaffen 99% der Menschen um mich herum nicht - was für eine Basis für Automatisierung!
Und darum geht es mir: mir gehen wirklich die Szenarien aus, wo LLMs mit etwas Tuning, RAG Modellen etc. _nicht_ zu "ready to ship" zu bringen sind. Da ist mir dann AGI ziemlich egal.
Gemini 3 Pro kann meine Handschrift lesen, und zwar perfekt. das schaffen 99% der Menschen um mich herum nicht - was für eine Basis für Automatisierung!
@rstockm Das Beispiel mit dem Zahlenratespiel gilt exakt so noch heute. Das eine LLM so ein Zahlenratespiel in Software gießen kann war nicht die Aufgabe, das ist trivial für eine LLM weil es dafür Millionen Codebeispiele gibt. “Ja, es kann das nicht aber dafür kann es was anderes” ist keine Lösung des Originalproblems.
@343max Oh das war ohne Software, nur über einen Prompt.

@rstockm Exakt. Du lässt die AI ein anderes Problem lösen als das was ich ihr gegeben hatte. Was ist damit bewiesen außer das es andere Probleme möglicherweise lösen kann. (Ich bezweifle übrigens nach wie vor, dass dein Beispiel besser funktioniert als meins, du hast es einfach nur viel komplexer gemacht, was es mühseliger macht die Schwächen zu finden. Abgesehen davon, dass es ein komplett anderer Prompt ist)
@343max Das ist mir als Produktmanager aber doch völlig egal. Es ist "ready to ship“, das zählt. Und es kann ja ausprobiert werden - funktioniert wunderbar und 100% zuverlässig.
@rstockm Aber MIR ist es nicht egal. MIR ist es schon wichtig, dass eine AI ein sehr einfaches Problem das jeder Mensch problemlos lösen kann von dem die AI behauptet es lösen zu können dann auch lösen kann. Ich habe dieses Beispiel gewählt, weil es sehr anschaulich macht, wie die AI es einfach per Design nicht kann.
@rstockm Du sagt “aber es kann ein komplett anderes Problem lösen und das reicht mir”. Okay. Aber stimmst du mir zu, dass es das eigentliche von mir beschriebene Problem nach wie vor nicht lösen kann?
@343max Ich glaube in der Sache sind wir gar nicht weit auseinander, wir haben nur sehr unterschiedliche Perspektiven auf die Grundfrage. These:
1)
Ralf: zentral ist, dass ein Problem verlässlich mit LLM gelöst werden kann. Egal wie der Weg ist.
Max: zentral ist: dass auch der komplette Weg vom LLM perfekt gegangen wird ohne Begleitung
2)
Ralf: nutzt ausschließlich die besten für Geld verfügbaren Modelle, ignoriert den Rest
Max: nutzt was gerade da ist, auch die freien Versionen
1)
Ralf: zentral ist, dass ein Problem verlässlich mit LLM gelöst werden kann. Egal wie der Weg ist.
Max: zentral ist: dass auch der komplette Weg vom LLM perfekt gegangen wird ohne Begleitung
2)
Ralf: nutzt ausschließlich die besten für Geld verfügbaren Modelle, ignoriert den Rest
Max: nutzt was gerade da ist, auch die freien Versionen
Die prinzipiellen Schwächen dieser Systeme ignoriert er oder erzählt mir das wenn ich nur wohlhabender wäre und 200€/Monat Abos hätte alles total toll wäre (kann ich halt nicht überprüfen und scheint mir auch nicht glaubhaft) (2/2)
@343max Das Schöne ist ja, dass es Forschung gibt und die ist bisher ziemlich eindeutig. Man fühlt sich als Softwareentwickler mit LLM-"Unterstützung " deutlich produktiver als man tatsächlich ist.

@rstockm @343max 2020 ist nicht ganz 10 Jahre her. Und ja, ich habe das Gefühl, dass es in den letzten 1-2 Jahren eher eine Stagnation gibt
@rstockm @343max Bisher hat mich noch kein LLM für die Softwareentwicklung überzeugt. Ja, die kotzen schnell einen Prototypen raus, aber sobald die echte Welt damit in Verbindung kommt, explodiert alles.
Für kleine Nischenprobleme kann es vielleicht was taugen, aber da sind spezielle Lösungen sicher besser als LLMs.
@lbenedix @343max Alles hier aus den letzten 2 Jahren dazu zwei nicht öffentliche die noch komplexer sind:
https://github.com/rstockm?tab=repositories
Es kommt halt auch darauf an ob man die LLMs beim Coden als Gegner sieht den man aufs Kreuz legen möchte oder als endlos geduldig motivierten Junior DEV den man ins eigene Projekt einarbeitet.

@343max @rstockm Bei der Beurteilung, ob ein LLM gute Arbeit macht, spielen viele psychologische Verzerrungen mit. Es fängt schon damit an, dass man selbst etwas tut, also einen Prompt formuliert und dann passiert etwas. Das ist natürlich toll.
Aber ja, es gibt glaub ich kein erfolgreiches Open Source Projekt, bei dem der überwiegende Anteil der Contributions von LLMs kommt. Oder?
@lbenedix @343max Schön, dass ihr euch einig seid, dass meine Apps alle unterkomplex sind. Was ich sagen kann:
1) ich habe keine Zeile davon selbst geschrieben
2) keines der Projekte hätte ich angefangen ohne LLMs (ich kann kein JavaScript)
3) die Oneshot Quote ist mit den Monaten kontinuierlich gestiegen, bei Testabend fast alles bis auf mobil CSS
4) Einigen der Tools würde ich doch gesellschaftlichen Nutzen zuschreiben wie Mastowall, Mastotags oder Fedipol.
1) ich habe keine Zeile davon selbst geschrieben
2) keines der Projekte hätte ich angefangen ohne LLMs (ich kann kein JavaScript)
3) die Oneshot Quote ist mit den Monaten kontinuierlich gestiegen, bei Testabend fast alles bis auf mobil CSS
4) Einigen der Tools würde ich doch gesellschaftlichen Nutzen zuschreiben wie Mastowall, Mastotags oder Fedipol.
@343max @lbenedix Das hier nehme ich häufig, wenn ich Leute verstören will:
„Programmiere eine Werbanwendung, wo ich auf einem Canvas farbige Zettel posten kann. Die Zettel sollen sich verschieben lassen, einen Titel haben und Text - alles soll editierbar sein. Über einen Selektor kann man die Farbe des Zettels wechseln, die Schrift soll sich in der Helligkeit dem Hintergrund anpassen für genug Kontrast.
1/2
@343max @lbenedix „Den Canvas möchte ich mit der Maus auch selbst verschieben können. Öffne die App im Browser-Tab deiner IDE, suche nach Fehlern auf der Konsole. Melde dich erst wieder, wenn du fertig bist.“
Das funktioniert immer, Ergebnis ist eine JS Webapp (das ist bei mir das vorgegebene Meta-Framework) die alle gewünschten Features drin hat und auf einem lokalen Python Server läuft.
2/2
@rstockm @lbenedix Ich habe das jetzt in Cursor ausgegeben, weil ich mal vermute, dass das die IDE ist die du meinst. Es startet einen Server der dann Seite ausliefert in der man Notizen hin und her ziehen kann. Die Schriftfarbe wird nur angepasst wenn man die Farbe ändert, nicht wenn man eine neue Notiz anlegt, das Canvas hat einen unsichtbaren Rahmen über den man Notizen nicht hinausziehen kann, der Code ist eher abenteuerlich. (1/2)
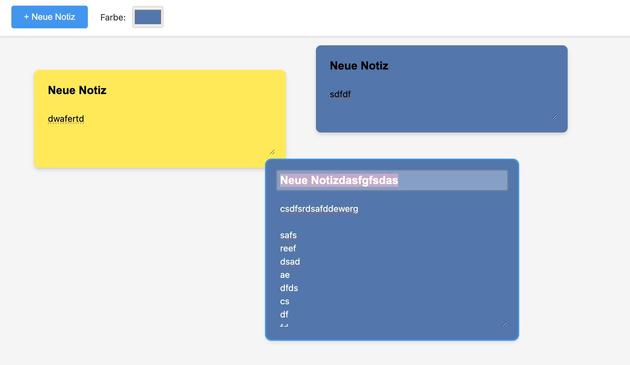

Den Teil deiner Anweisung das es das ganze doch bitte in einem Browser testen soll hat es einfach an mich weiter delegiert, dass ich das doch selbst machen soll. Ich bin jetzt nicht so wahnsinnig verstört, weil ich schon schlimmeres gesehen habe. Aber ist das jetzt irgendwas anderes als dieser typische AI-Slop, den man von LLMs so erwartet? (2/2)
@343max weclhes Modell hast du in Cursor genommen? Composer 1 (von Cursor selbst) ist darauf trainiert die Tools der IDE selbst zu nutzen, da klappt das mit internem Browser/Console etc. gut.
Du wolltest 2 Beispiele, die habe ich rausgesucht (das erste mal angeschaut)? Dass die jetzt auch wieder nicht reichen - tja ist jetzt halt so, auch wenn ich noch 20 weitere raussuche (die ich hätte in meinen Histories) wäre immer etwas falsch/nicht genug.
Weil halt nicht sein kann, was nicht sein darf. 1/2
Du wolltest 2 Beispiele, die habe ich rausgesucht (das erste mal angeschaut)? Dass die jetzt auch wieder nicht reichen - tja ist jetzt halt so, auch wenn ich noch 20 weitere raussuche (die ich hätte in meinen Histories) wäre immer etwas falsch/nicht genug.
Weil halt nicht sein kann, was nicht sein darf. 1/2
@343max Was ich aber aus täglicher Erfahrung sicher sagen kann: vor einem Jahr waren solche 1Shots wie meine beiden Beispiele völlig undenkbar. Was wird dann also in 1 und 5 Jahren sein? Und dann bin ich genau bei dieser Studie von vorhin.

Ralf Stockmann (@[email protected])
Attached: 1 image @lbenedix @[email protected] Sehr schöne Seite, danke dafür. Direkt eine Studie darüber aber so:

Measuring AI Ability to Complete Long Tasks
Despite rapid progress on AI benchmarks, the real-world meaning of benchmark performance remains unclear. To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes. Furthermore, frontier AI time horizon has been doubling approximately every seven months since 2019, though the trend may have accelerated in 2024. The increase in AI models' time horizons seems to be primarily driven by greater reliability and ability to adapt to mistakes, combined with better logical reasoning and tool use capabilities. We discuss the limitations of our results -- including their degree of external validity -- and the implications of increased autonomy for dangerous capabilities. If these results generalize to real-world software tasks, extrapolation of this trend predicts that within 5 years, AI systems will be capable of automating many software tasks that currently take humans a month.