Sehr schöner ChatGPT Takedown an einem sehr simplen aber extrem lustigen Beispiel https://mindmatters.ai/2025/08/chatgpt-5-tries-out-rotated-tic-tac-toe-you-be-the-judge/



@rstockm Abgesehen davon, dass ich so eine „aber dieses 0.0.1 Update ändert alles“ Argumentstion sehr dünn finde. ChatGPT 5.2 ist kaum mehr als ein marketing Update über 5.0, es ändert nichts daran wie diese Modelle funktionieren und ändern somit auch nichts an der fundamentalen Kritik selbst wenn die neue Version bei dem konkreten Beispiel vielleicht marginal besser abschneidet.
@343max Na ja, es ist aber halt andersrum: dieses „Beispiel" funktioniert bei exakt KEINEM der aktuellen Flagship-Modelle. Getestet: Mistral (lokal!), Gemini 3 Pro, ChatGPT 5.2, Claude Sonnet 4.5.
Keines fällt darauf rein, die Antwort von Gemini mal als hübsches Beispiel.
Und so läuft das seit 2 Jahren:
10 „haha, schaut was die GPTs alles nicht können"
20 ich setze mich 1 Minute dran und exakt das funktioniert in allen neuen Modellen
30 goto 10
🤷🏻♂️

@rstockm Aber ich habe dir doch eben einen Screenshot geschickt wie das aktuelle ChatGPT genau darauf reinfällt.
Für mich ist es exakt andersrum wie du beschreibst. Seit Jahren:
10 du und andere AI believer: “ja, noch vor ein paar Wochen war das Modell noch strunzdumm, aber heute können sie exakt dieses eine Beispiel lösen, darum sind sie perfekt”
20 jemand findet ein neues Beispiel wie ein "Flagship-Model" haarstäubend dumme weise auf die Fresse fällt… (1/2)
30 die AI Firmen bringen neue Modelle raus die auf exakt diesen Fall nicht mehr reinfallen
40 goto 10
le sigh
Wir haben exakt die selbe Diskussion schon diverse Male geführt. Was bringt dich auf die Idee das ChatGPT 5.2.4 Code Red Edition dieses mal aber wirklich all die Versprechen einlöst, die all die anderen Versionen nicht einlösen konnten? (2/2)
@343max Ich rede nicht von ChatGPT sondern generell von den rechts unten Modellen, auch der anderen Hersteller. Bei deinen Screenshot kann ich nicht sehen, welches das ist. Das mit Abstand beste Besispiel das du bisher hattest war das Zahlenraten-Spiel, weil es so hübsch die Schwäche von LLM (will alles könne) mit den Limitierungen (unfähig, eigene Grenzen zu erkennen) exploited hat. 1/2
@343max Aber auch dort habe ich in 20 Minuten einen Weg gefunden (dank KI) um dieses Spiel auf beliebigen LLMs zu 100% perfect „ready to ship“ laufen zu lassen.
Und darum geht es mir: mir gehen wirklich die Szenarien aus, wo LLMs mit etwas Tuning, RAG Modellen etc. _nicht_ zu "ready to ship" zu bringen sind. Da ist mir dann AGI ziemlich egal.
Gemini 3 Pro kann meine Handschrift lesen, und zwar perfekt. das schaffen 99% der Menschen um mich herum nicht - was für eine Basis für Automatisierung!
Und darum geht es mir: mir gehen wirklich die Szenarien aus, wo LLMs mit etwas Tuning, RAG Modellen etc. _nicht_ zu "ready to ship" zu bringen sind. Da ist mir dann AGI ziemlich egal.
Gemini 3 Pro kann meine Handschrift lesen, und zwar perfekt. das schaffen 99% der Menschen um mich herum nicht - was für eine Basis für Automatisierung!
@rstockm Das Beispiel mit dem Zahlenratespiel gilt exakt so noch heute. Das eine LLM so ein Zahlenratespiel in Software gießen kann war nicht die Aufgabe, das ist trivial für eine LLM weil es dafür Millionen Codebeispiele gibt. “Ja, es kann das nicht aber dafür kann es was anderes” ist keine Lösung des Originalproblems.
@343max Oh das war ohne Software, nur über einen Prompt.

@rstockm Exakt. Du lässt die AI ein anderes Problem lösen als das was ich ihr gegeben hatte. Was ist damit bewiesen außer das es andere Probleme möglicherweise lösen kann. (Ich bezweifle übrigens nach wie vor, dass dein Beispiel besser funktioniert als meins, du hast es einfach nur viel komplexer gemacht, was es mühseliger macht die Schwächen zu finden. Abgesehen davon, dass es ein komplett anderer Prompt ist)
@343max Das ist mir als Produktmanager aber doch völlig egal. Es ist "ready to ship“, das zählt. Und es kann ja ausprobiert werden - funktioniert wunderbar und 100% zuverlässig.
@rstockm Aber MIR ist es nicht egal. MIR ist es schon wichtig, dass eine AI ein sehr einfaches Problem das jeder Mensch problemlos lösen kann von dem die AI behauptet es lösen zu können dann auch lösen kann. Ich habe dieses Beispiel gewählt, weil es sehr anschaulich macht, wie die AI es einfach per Design nicht kann.
@rstockm Du sagt “aber es kann ein komplett anderes Problem lösen und das reicht mir”. Okay. Aber stimmst du mir zu, dass es das eigentliche von mir beschriebene Problem nach wie vor nicht lösen kann?
@343max Ich glaube in der Sache sind wir gar nicht weit auseinander, wir haben nur sehr unterschiedliche Perspektiven auf die Grundfrage. These:
1)
Ralf: zentral ist, dass ein Problem verlässlich mit LLM gelöst werden kann. Egal wie der Weg ist.
Max: zentral ist: dass auch der komplette Weg vom LLM perfekt gegangen wird ohne Begleitung
2)
Ralf: nutzt ausschließlich die besten für Geld verfügbaren Modelle, ignoriert den Rest
Max: nutzt was gerade da ist, auch die freien Versionen
1)
Ralf: zentral ist, dass ein Problem verlässlich mit LLM gelöst werden kann. Egal wie der Weg ist.
Max: zentral ist: dass auch der komplette Weg vom LLM perfekt gegangen wird ohne Begleitung
2)
Ralf: nutzt ausschließlich die besten für Geld verfügbaren Modelle, ignoriert den Rest
Max: nutzt was gerade da ist, auch die freien Versionen
@rstockm Welche halbwegs komplexen Probleme können LLMs denn verlässlich (also: selbständig ohne Kontrolle in sagen wir mal 99,9% der Fälle korrekt) lösen? (1/2)
@343max Frisch auf der Arbeit getestet: die Überführung eines 3 x 2 Meter Whiteboards, gefüllt mit etwa 100 Post-IT Zetteln geschrieben von 8 verschiedenen Personen.
Ein normales iPhone-Bild davon überführt die LLM in eine Markdown-Datei und clustert dann noch sinnvoll. Ich hätte das bis vor 1 Monat für technisch völlig unmöglich gehalten, Gemini 3 Pro macht das tiefenentspannt. Das ist ein totaler Game-Changer für unsere Strategiearbeit.
Rückwärts geht auch: Whiteboard aus 5-Seiten PDF
Ein normales iPhone-Bild davon überführt die LLM in eine Markdown-Datei und clustert dann noch sinnvoll. Ich hätte das bis vor 1 Monat für technisch völlig unmöglich gehalten, Gemini 3 Pro macht das tiefenentspannt. Das ist ein totaler Game-Changer für unsere Strategiearbeit.
Rückwärts geht auch: Whiteboard aus 5-Seiten PDF
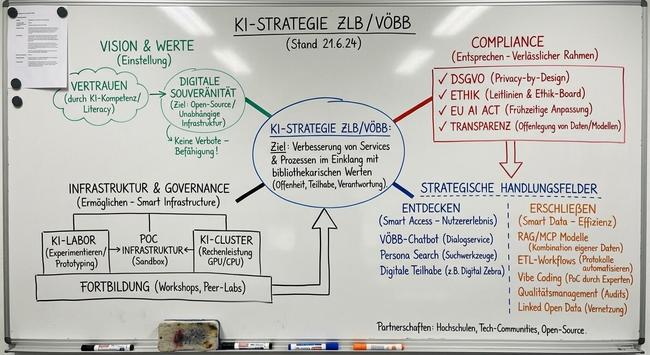
@343max Das ist die nächste eingebrochene Mauer: "LLMs können keine Schrift - weder lesen, noch zeichnen“.
@rstockm Wer hat wann gesagt das AI keine Schrifterkennung kann? Nach meinem Wissen ist die Erkennnung von Handschrift eines der ersten Probleme überhaupt das sehr erfolgreich mit AI gelöst wurde. Ich habe mal so 2017 ein AI Tutorial gemacht, das ging um die Erkenunng von ZIP Code und eine AI auf einem Laptop auf eine 99,99% Treffsicherheit bei der Erkennung von ZIP Codes zu trainieren war schon damals ein simples Anfängerproblem.
@rstockm Und: was soll ich mit diesem Bild? Ich weiß nicht was auf den Post Its stand. Ich weiß nicht, welche Themen ihr da wirklich aufgeschrieben habt. Ich kann nicht prüfen, welche Themen die AI vergessen hat. Ich kann nicht prüfen, was sie dazu erfunden hat. Ich sehe eine Tafel im typischen AI generierten 0815 Look mit für mich sehr generischen Inhalten.
Was mir auffällt: Befähigung schreibt man mit “ä" und nicht mit einem a mit Häkchen drüber.

@343max Das ist nicht von dem Whiteboard sondern aus meinem 5-Seiten Strategie-PDF Fließtext generiert. Und das muss du mir jetzt halt mal glauben: das ist schlicht perfekt. Absolut nichts hinzu erfunden. Alles Relevante berücksichtigt. Da hätte ich sonst jemanden ca. 3h dran gesetzt.
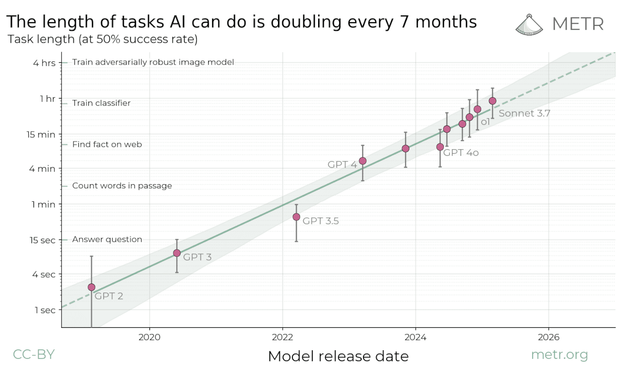
@rstockm @343max "current models have almost 100% success rate on tasks taking humans less than 4 minutes, but succeed <10% of the time on tasks taking more than around 4 hours"
Einen 3h-Task würde ich eher keinem LLM geben.
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/