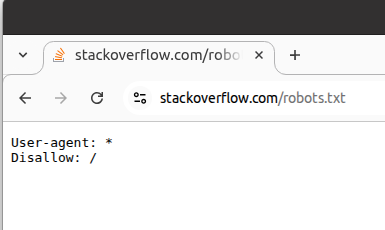
Tried to use /robots.txt to tell bots to stay out. The bots' response: "Your rules are adorable. Now, where's the content? Hmm, what's this 'disallow' thing? Looks like a suggestion for a really fast crawl!" *om nom om nom*
PS: As per that SO's robots.txt file, Google, Yahoo, DuckDuckGo, Bing, or LLM/AI (or anyone) should not show SO content, yet they all ignore it. Moral of the story for developers: robots.txt files are useless these days. They don't follow rules.