
oh you grew up watching tiktok? i grew up searching for aliens
@valkyrie I know some people who searched for aliens. They had a cast-off dish (inherited from Philips I think) in the garden (three or four metres?) and a rack of electronics analysing the signal in real time.
They had to remember to turn off the bleeper when they had party guests crashing on the floor, else the false positives work them up in the middle of the night.

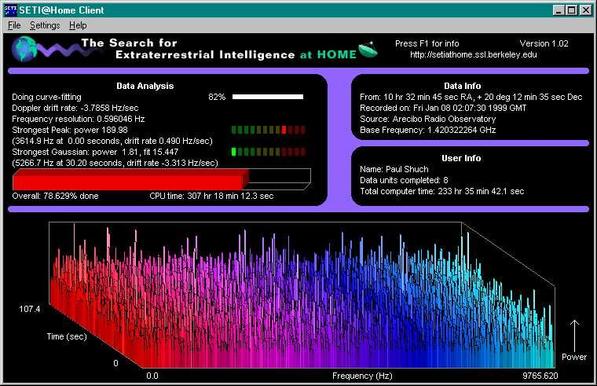
My SETI@home stats:
Total credit 39,577,723
Recent average credit 62.55
SETI@home classic workunits 250
SETI@home classic CPU time 3,231 hours
@Theramansi @valkyrie I can still log into my account! 😀
34 classic work units
1610 hrs classic CPU time
core memory unlocked
I deep-dived into the “final results” after they decommissioned it (after all, I contributed lots of CPU), and I think there were a dozen candidates sent for review — with no further news
But the retirement of distributed processing was also fascinating — I think it became “too much data” which is ironic, because it was supposed to scale up for exactly that; but it was the transport of the data that was harder at “very” large scales, surpassing even the challenge of processing it
So in a weird summary:
- Small data: trivial to move, easy to process local
- Large data: takes work to distribute broadly, but more viable to process distributively
- Very large data: impossible to distribute, but recently viable to process on-site or multi-site
So what it reminds me of is ARPANET, the academic networks predating the public internet



 💾
💾

