Claire Huang wrote an undergraduate honor's thesis, supervised by @steveblackburn and @caizixian https://www.steveblackburn.org/pubs/theses/huang-2025.pdf
She uses sampling PEBS counters and data linear addressing (DLA) on Intel chips to attempt to understand the structure and attribution of load latencies in MMTk.
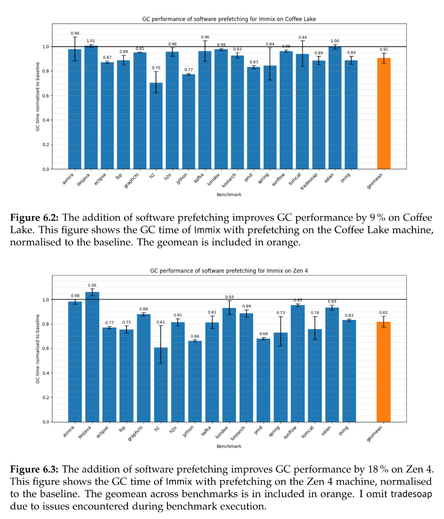
After identifying L1 misses in the trace loop as a significant overhead, she adds prefetching and reduces GC time by 10% or so across a range of benchmarks, and more on Zen4.