#BabelOfCode 2024
Week 9
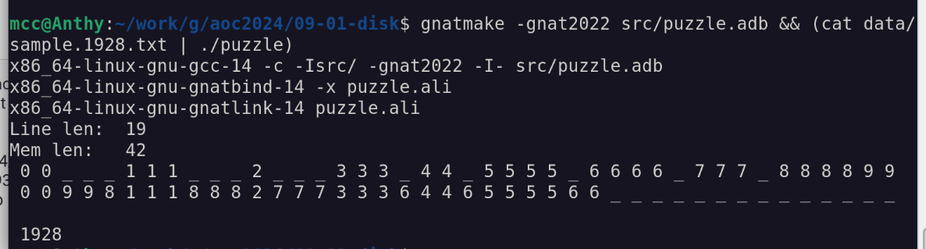
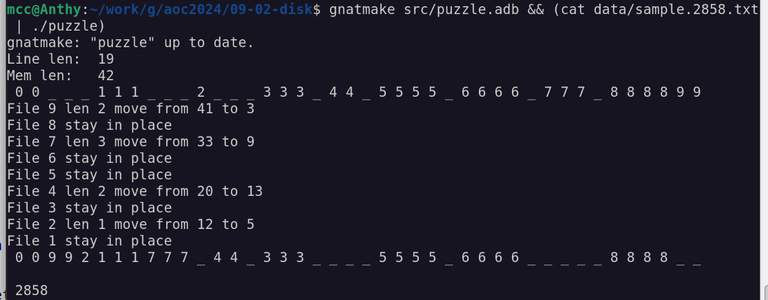
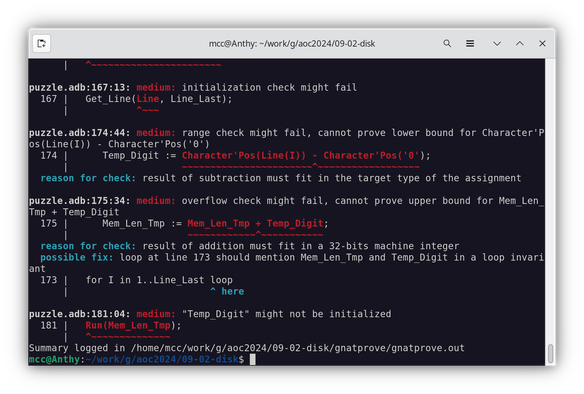
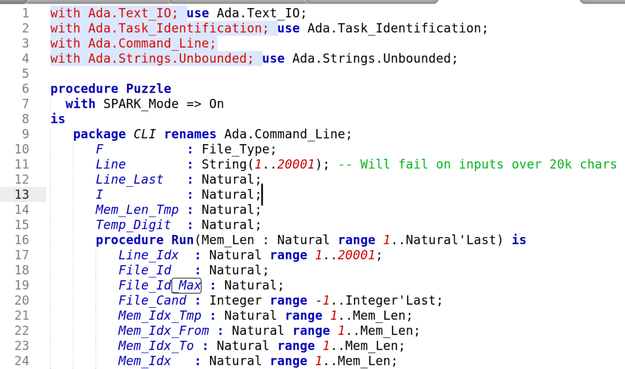
Language: Ada (Spark?)
Confidence level: High
PREV WEEK: https://mastodon.social/@mcc/114463342416949024
NEXT WEEK: https://mastodon.social/@mcc/114582208242623432
So I start reading the manual for Ada. I think: This is *great!* This has all these features, conveniences etc I was wishing for for years in C++, and didn't get until I jumped to Rust. I might have been using this for games in 2010 if I'd dug into it then!
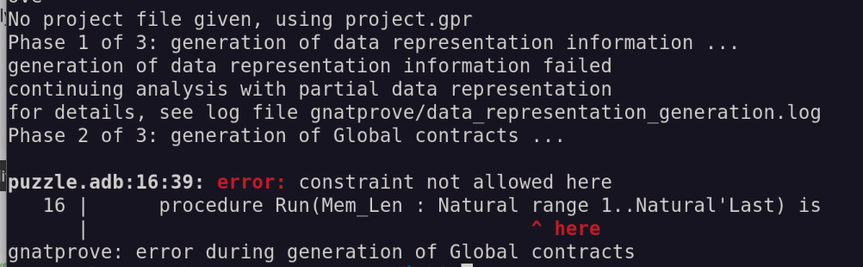
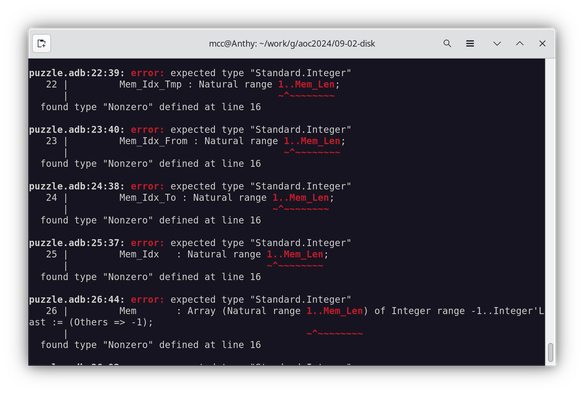
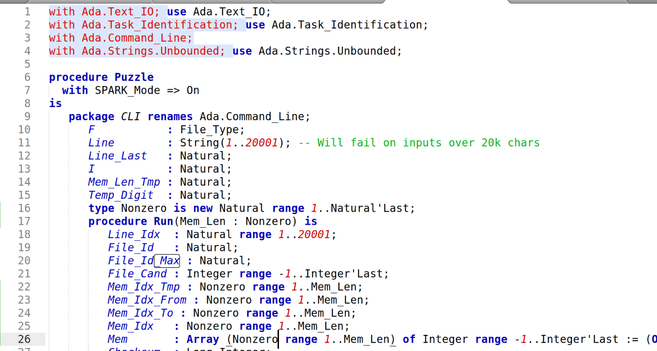
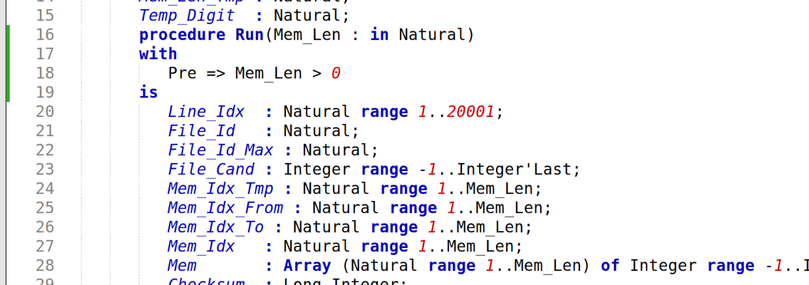
Then I start writing an actual Ada program. It turns out to be basically a pain in the ass.