HPC woes:
5 * MONs with 2 * 100 Gb/s links each
16 OSDs with 2 * 100 Gb/s links each and 1 * 15 TB NVMe each rated at 5,5 GiB/s at 128 KiB IO write
fio says 👌
iperf3 says 👌
Ceph:

HPC woes:
5 * MONs with 2 * 100 Gb/s links each
16 OSDs with 2 * 100 Gb/s links each and 1 * 15 TB NVMe each rated at 5,5 GiB/s at 128 KiB IO write
fio says 👌
iperf3 says 👌
Ceph:
@blmt Sure thing!
The NVMe's in question are of model "KCD6XLUL15T3"
https://americas.kioxia.com/content/dam/kioxia/shared/business/ssd/data-center-ssd/asset/productbrief/dSSD-CD6-R-product-brief.pdf
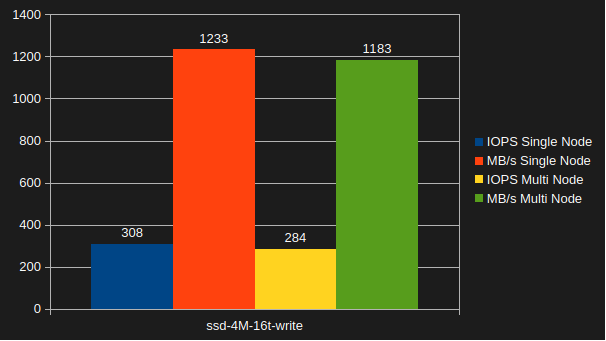
No CephFS, RBD or RGW at this point. This cluster is installed with RHCS 7 (18.2.1-298 to be exact), there are two OSD's/NVMe, just one pool for now, 2048 PG's in the pool with the autoscaler set to only warn and one client doing this:
# rados bench -p radosbench_ssd 60 write -b 4M -t 16 --run-name $(hostname -s) --no-cleanup
@blmt Haha, yes we are quite puzzled as well! 😄
Although I think (hope) the issue is with the autoscaler setting way too few PGs per pool.
You can create a new pool and set 2048 PGs and then have autoscaler be like: "No actually, there's no data in that pool so I'll scale that down to...mmm...1" 😄
We've changed autoscaler to "warn" now and set the number of PGs back to 2048, and are waiting for the cluster to recover before testing again. I'll report back when the testing is redone.