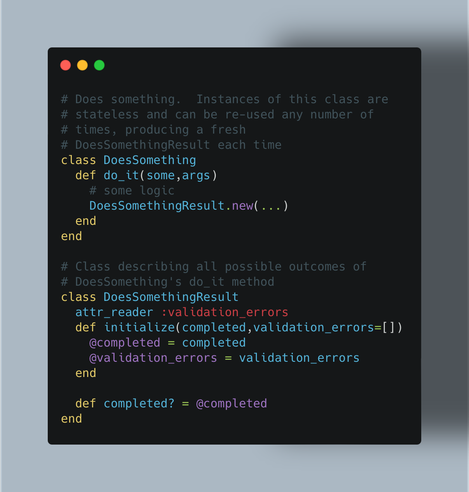
Two OO ways to design something, curious what everyone's thoughts are? This is w/out context of a framework, just purely OO perspective.
Option 1 - Stateless object w/ Rich Result
Option 2 - Stateful object (e.g. command pattern + internal state to store results)
https://gist.github.com/davetron5000/19aa850df641be6c334e9b64a944b6c8
My thoughts follow, but I am not sure which is the "best" pattern - again all things being equal/not in Rails/etc.