I have a preprint out estimating how many scholarly papers are written using chatGPT etc? I estimate upwards of 60k articles (>1% of global output) published in 2023. https://arxiv.org/abs/2403.16887
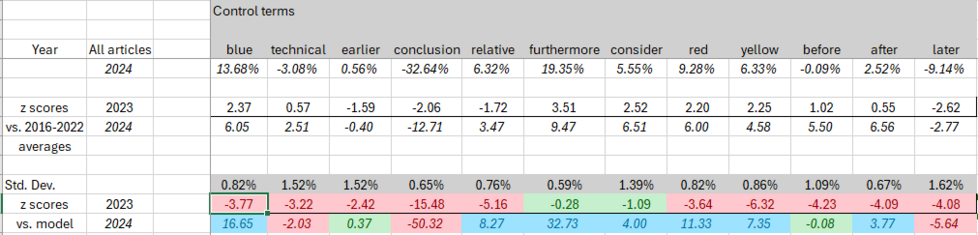
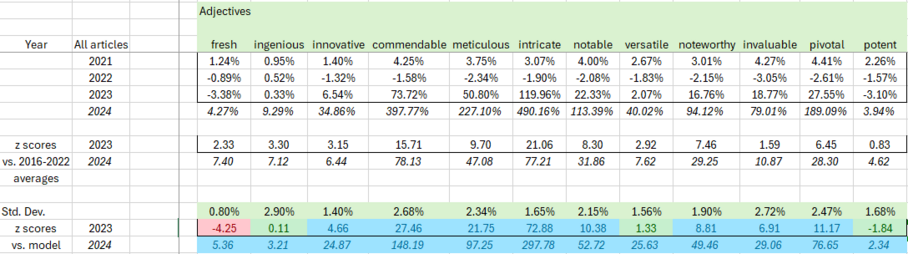
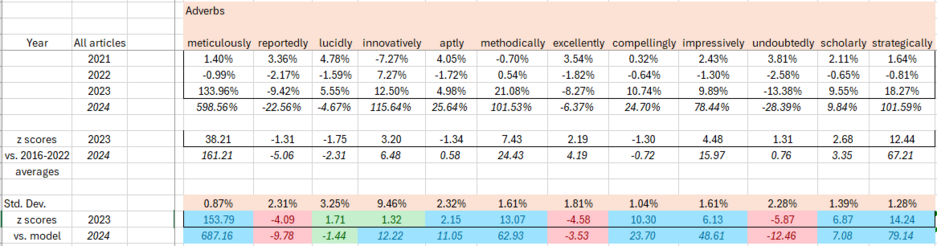
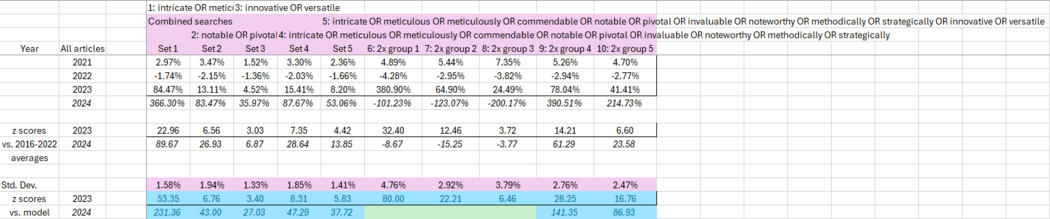
How can we identify this? Simple: there are certain words that LLMs love, and they suddenly start showing up *a lot* last year. Twice as many papers call something "intricate", big rises for "commendable" and "meticulous".


ChatGPT "contamination": estimating the prevalence of LLMs in the scholarly literature
The use of ChatGPT and similar Large Language Model (LLM) tools in scholarly communication and academic publishing has been widely discussed since they became easily accessible to a general audience in late 2022. This study uses keywords known to be disproportionately present in LLM-generated text to provide an overall estimate for the prevalence of LLM-assisted writing in the scholarly literature. For the publishing year 2023, it is found that several of those keywords show a distinctive and disproportionate increase in their prevalence, individually and in combination. It is estimated that at least 60,000 papers (slightly over 1% of all articles) were LLM-assisted, though this number could be extended and refined by analysis of other characteristics of the papers or by identification of further indicative keywords.