I can't figure out how it's determining when filenames end, though.
Maybe it's assuming they all have extensions and all extensions are 3 letters long?
that makes some of the files make sense and some of the others not make sense!
oh god there is compression
not all files are compressed. but some are
found the code where it parses the PAC headers.
It's terrible as expected.
The pre-pac header stuff gives you a pointer into each header, but then the fun part is that the pointer is not to the beginning, it's to the middle. So it looks things up by indexing forward AND backward
so the filename starts at the offset of, uh, negative 28
and here's how it determines the ending: it's until it hits a 0, OR the filename ends up being 12 characters long.
FUCK
someday I'm gonna reverse engineer a game and not want to timetravel back to its creation and ask them WHAT THE FUCK at gunpoint
sometimes I won't even ask, I'll just start shooting
so I'm just gonna take all my current PAC parsing code and throw it out and replace it with the nonsense of the actual code.
that was my fatal mistake: I was writing parsing code assuming this shit made any fucking sense
also I think there's a mistake in this code OR ghidra is decoding it incorrectly.
it seems to be trying to ensure all filenames are uppercase, but because it's wrong, it is corrupting all non-lowercase characters.
they might not have noticed if they apply the same "uppercase" transformation when trying to load filenames, because both would be corrupted in the same way
okay so now I've got working filenames, offsets, lengths, and compressed lengths. So I can find out what files are where and if they're compressed. I can't uncompress them yet.
I have located the decompression routine.
now to try to figure out what the fuck it does
this decompression routine is big-endian.
on a little-endian system.
it seems it's loading 16bit lengths, then using the top 15 bits? with the lowest bit as a flag?
I don't recognize this. I don't think it's DEFLATE
so looking at this code, it doesn't seem to involve huffman encoding. there's no tables, just some look-back with a sliding (I think?) window.
So this is just a slightly fancy RLE, I think?
I'm gonna try to bypass figuring out the compression right now by just stuffing the ghidra code into a C program and calling it from python
Bingo. it works!
Mostly. my output file is always 64mb but that's because I don't have a good way to tell how big it should be
even more bingo.
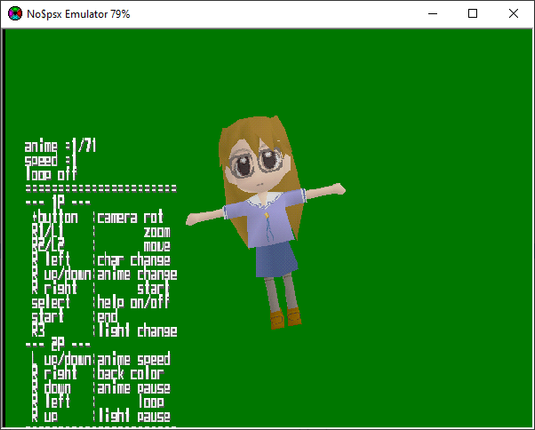
I have textures now.
there's some weird-ass shit going on here. like, the datafiles have some PAC chunks with type 36.
As far as I can tell, there's no code that handles chunk-36.
So the only way that makes sense is if part of the game dynamically loads code which then registers a chunk-36 parser
so each character is stored in a a PAC file under viewer\ (inside AZU.APF)
So like, the first Chiyo-chan is chi_v.pac
That PAC file contains 91 texture images and a 95 kilobyte GMD file, which seems to contain all the geometry AND animations.
so the next step is to figure out how GMD works.
Fortunately I know where the function that parses it starts
the code also seems to handle decoding two versions of the GMD format, but I can only find one in use in the datafiles.
Maybe they used the other in the One Piece games, and just never dropped support?
oh hello. I took a quick look at the second of the One Piece games, and it turns out they did the same thing as Azumanga and included the executable inside the APF file... but they did it twice, and the two don't match!
and it looks like that for the second One Piece game, it uses .TMD files, which have a completely different header than the two supported by azumanga
ahh. it looks like the GMD format gets loaded recursively, and I bet that's why there are a total of 3 (not 2, as I suspected) different versions of it.
I bet versions 1 and 0 appear inside version 2
interesting string:
"This is Technosoft\'s communication shell password"
Technosoft is the company that game before Ganbarion. Apparently they built some kind of communication shell utility for their PS1 games
ugh I'm not being paid enough for this.
so it seems there's a complex function-pointer system used so that the main loop can stay the same, and it can be overwritten by overlays loaded from the APF files
but it's a ton of function pointers being thrown around and it just makes me go crosseyed
return (int)*(short *)(**(int **)(*(int *)(param_1 + 0xc) + 0x14) + 0x10);
C is such a simple and expressive language
sometimes immense reverse engineering progress just looks like Yomi-at-an-angle
okay I have figured out where most of the controller logic for the char viewer is, and thus I know which function is called when it needs to load a new character
but reversing that will have to wait until tomorrow. I am fried
load_new_character
so fried I randomly pasted the name of the function at the end of that comment
these programmers did not have a compiler that was good at optimizing overlays.
I keep tracing through a complicated tree of functions in the overlay, then discovering an identical set of functions in the non-overlay.
and they're not in the part that gets overlaid: they're always visible
so it seems the way this PAC format works is that there's an idea of a PAC-chunk-handler-list, which is a collection of approximately 47 callbacks for each of the chunk types.
But when a PAC file needs to be loaded for a special reason, you can pass a different pac-chunk
-handler-list.
reverse engineering C code is always so much better when it's 90% callbacks and function pointers
I'm now at the "corrupt data while it's being loaded and see what breaks" stage of reverse engineering.
I haven't learned much, but I do now know a bunch of a bytes you shouldn't change or "the polygons will get all fucked"
@foone So, basically the stage neurology was at when they were guessing what bits of the brain do by seeing what was fucked up in people with various head injuries.
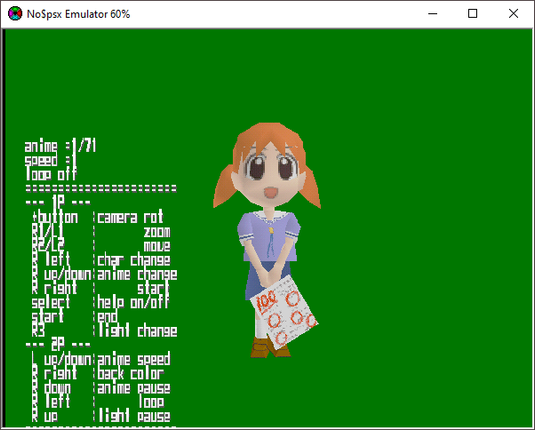
@petealexharris yep. Chiyo-Chan is my Phineas Gage