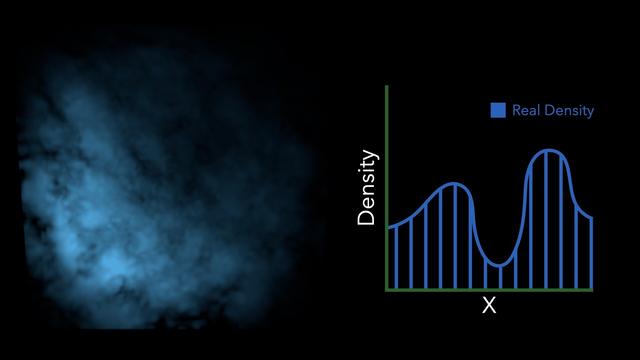
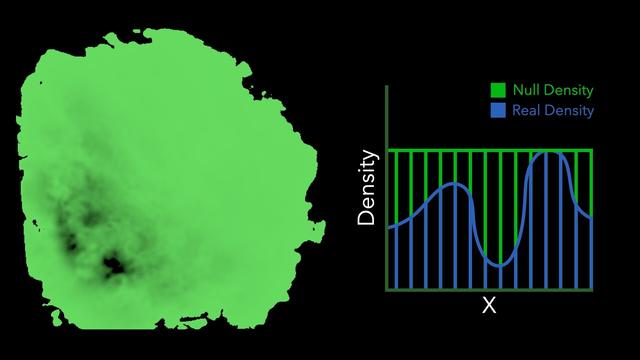
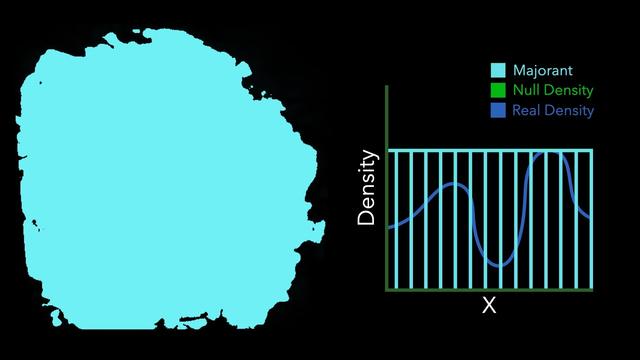
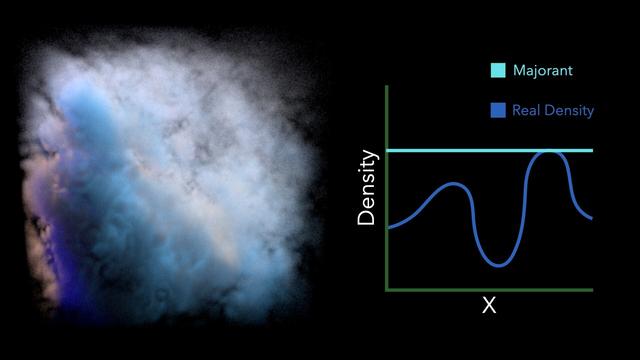
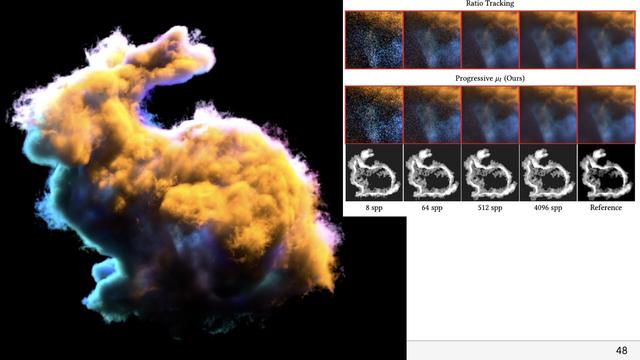
Our paper solves this problem, and the key idea is extremely simple.
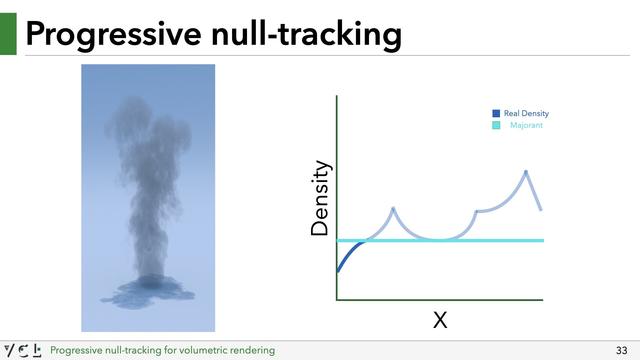
We just take a guess at a majorant. This guess doesn't have to be correct, or even close to correct. It could in fact just be a super tiny value to start off with.
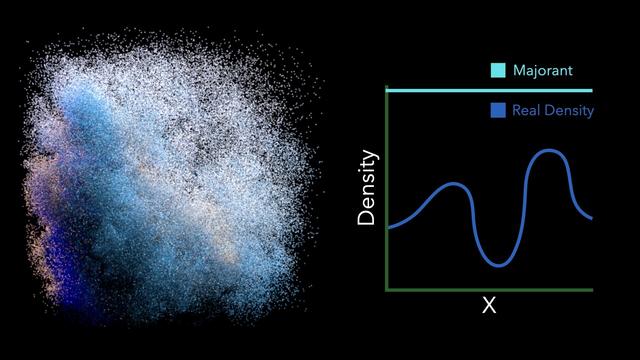
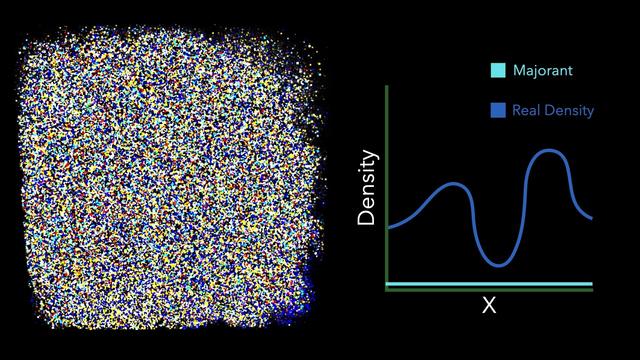
Given the current guess, we *clamp* the density of the medium to this current majorant. By clamping the medium, the majorant becomes bounding, so variance will be low, but we've changed the appearance of the medium (by making it lower density) which gives us a *biased* rendering.
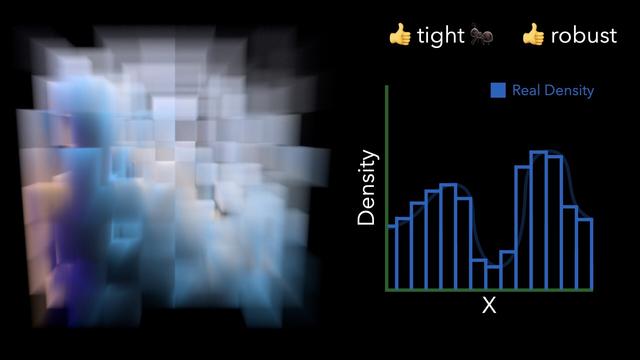
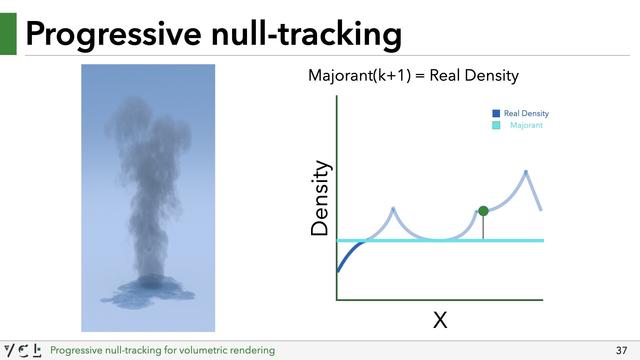
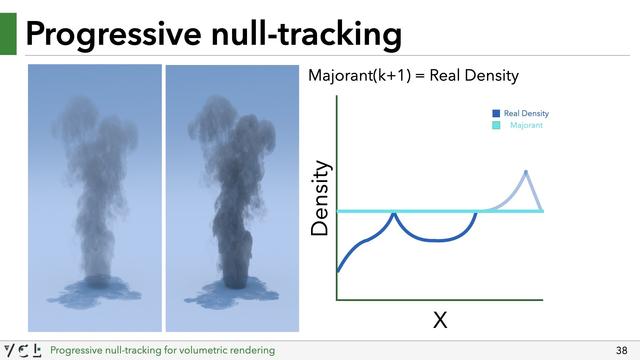
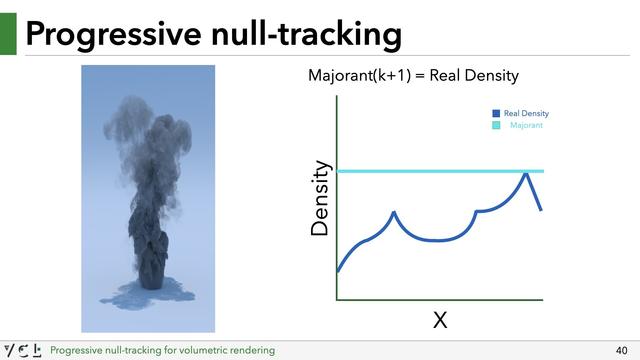
That's ok though, while rendering the first image, we end up sampling the medium at various locations, and can incrementally learn a new majorant (by e.g. taking the maximum density of all previous lookups). We can then render another image with an updated majorant. The medium densities are clamped again, but to this new improved majorant. The result may still be biased, but less so.