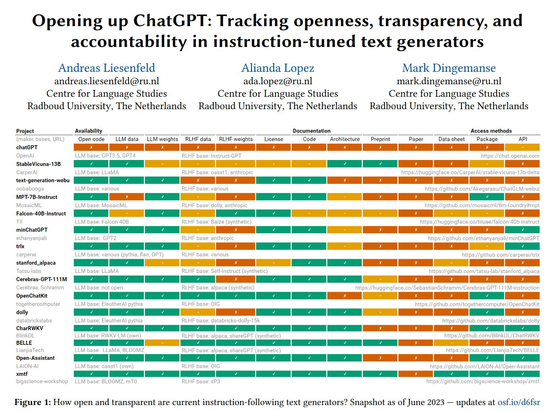
⚡️New! Opening up ChatGPT
https://dl.acm.org/doi/10.1145/3571884.3604316 (  https://doi.org/10.48550/arXiv.2307.05532 )
https://doi.org/10.48550/arXiv.2307.05532 )
TL;DR #chatgpt is unfit for responsible use in science & education. Open instruction-tuned text generators (LLM + RLHF) are on the rise. But how open are they? We track degrees of openness in this #CUI23 paper & live at https://opening-up-chatgpt.github.io
We hope this paper & repository will help more people make mindful choices about tech
work with @andreasliesenfeld and @alianda