K.Ishi@生成AIの産業応用 (@K_Ishi_AI)
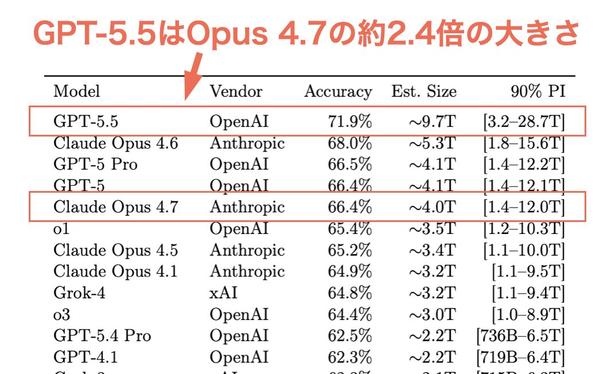
AI 모델 크기 추정 연구를 인용하며 GPT-5.5가 Claude Opus 4.7보다 약 2.4배 크고, 다른 모델들보다도 크게 앞선다고 주장합니다. 반면 Opus 4.7은 4.6 대비 약 25% 축소되었다는 분석도 포함된 모델 규모 관련 트윗입니다.
K.Ishi@生成AIの産業応用 (@K_Ishi_AI)
AI 모델 크기 추정 연구를 인용하며 GPT-5.5가 Claude Opus 4.7보다 약 2.4배 크고, 다른 모델들보다도 크게 앞선다고 주장합니다. 반면 Opus 4.7은 4.6 대비 약 25% 축소되었다는 분석도 포함된 모델 규모 관련 트윗입니다.
IT navi (@itnavi2022)
LLM의 지식량을 바탕으로 모델 크기를 추정하는 논문 방법을 소개합니다. 추정 오차가 약 3배 정도까지 가능해 GPT-5.5가 Opus 4.7보다 반드시 더 크다고 단정할 수는 없다는 점을 언급한 AI 연구 관련 트윗입니다.
Nico Martin (@nic_o_martin)
브라우저에서의 LLM 데모 초기 목표였던 10–20 tps보다 10배 빠른 성능과 더 나은 모델을 달성했다는 감탄의 트윗입니다. 현재는 초당 40토큰 수준에 모델 크기가 약 750MB에 불과하다고 하며, @xenovacom과 @liquidai의 작업을 칭찬하고 있습니다. 웹에서 실용적 LLM 배포 가능성을 시사합니다.
AISatoshi (@AiXsatoshi)
MiniMax-2.5 모델의 용량/크기를 간단히 표시한 트윗으로, 해당 모델이 230GB임을 알립니다. 모델 파일 크기 정보는 배포·호스팅, 추론 인프라 설계(메모리·디스크 요구)와 직접 연관됩니다.
AISatoshi (@AiXsatoshi)
GPT-5.3-Codex-Spark와 GLM-5의 모델 크기가 비슷하다는 관찰을 담은 짧은 언급입니다. 두 최신 모델의 규모 비교에 대한 간단한 코멘트입니다.
AISatoshi (@AiXsatoshi)
INT4 양자화 버전의 모델 용량이 405GB로 보고되었습니다. 해당 트윗은 INT4 양자화 적용 모델의 저장·배포 요구량을 간단히 알리는 내용으로, 로컬 실행 환경에서의 용량 계획에 참고가 됩니다.
parth (@parthsareen)
q4(퀀타이즈된 모델)가 약 22GB를 차지해 저장·메모리 측면에서 다소 타이트할 수 있지만, 모델 자체 성능은 매우 좋다는 간단한 평가입니다. 모델 용량과 리소스 요구 관련 실무적 주의가 필요함을 시사합니다.
J. Iwasawa (@jiwasawa)
Gemini 3 Pro가 5~10조(테라) 파라미터 규모일 것이라는 예측을 소개하는 트윗입니다. 해당 예측은 Artificial Analysis 창업자들이 오픈 모델의 AA-Omniscience Index와 총 파라미터 수의 관계를 외삽해 도출한 것이며, Gemini 3 Pro의 AA-Omniscience Index를 13으로 예상합니다.
mburaksayici đang phát triển smallevals - mô hình ngôn ngữ nhỏ để đánh giá RAG/VectorDB nhanh hơn. Với dataset 200k cuộc hội thoại (250 token/trung bình), anh ấy đào tạo mô hình 0.5-0.6B. Tuy nhiên, full fine-tuning làm giảm hiệu suất, nên chuyển sang LORA (20M tham số). Anh ấy đang tìm hiểu tỉ lệ hiệu quả giữa token đào tạo và quy mô LORA/mô hình. #AI #MachineLearning #LORA #ModelSize #Knowledge #AIvie #MLVn #LORAtrain
200k hội thoại → 250 token/tr. Mô hình 0.6B + LORA (20M) chưa tối ưu. Cần p
C Alcal 120B và phiênfriends Guoá. Chi tiết về 88GB vs 65GB, înt vyt 4bit & cần GGUF. Thông tin hữu ích cho ngườiution! #TechNews #AI #GPToss #VietnameseAI #Llama #OpenSource #ModelSize"
https://www.reddit.com/r/LocalLLaMA/comments/1oa3u2d/the_size_difference_of_gptoss120b_vs_its/