Vandaag is de locatie de HackaLOD2026 bekend gemaakt: Middelburg, in de Nieuwe Kerk, onderdeel van de Abdij. Opnieuw een hele bijzondere locatie! De inschrijving start binnenkort... #netwerkdigitaalerfgoed #hackalod #linkeddata

Just shipped a cool feature in LDView: URI Proxy!
Browse Linked Data from any external SPARQL endpoint as if it's local. No data copying, no duplication—just a unified view into distributed sources.
Some online examples:
https://data.digitopia.nl/uri:http://data.bibliotheken.nl/id/nbt/p17356755X
https://data.digitopia.nl/uri:https://data.ldmax.nl/ark:/74905/00fb35d26d83d8cce2a9b8acb29464af
https://data.digitopia.nl/uri:https://data.razu.nl/id/object/nl-wbdrazu-k50907905-689-11
Super for cultural heritage portals aggregating collections from multiple institutions.
Source at https://codeberg.org/renevoorburg/ldview
eyeling — a compact Notation3 (N3) reasoner in JavaScript.
The core idea: forward chaining is the outer loop; backward chaining is the proof engine used inside rule firing. Built-ins can participate in rule bodies, so consequences are computed until fixpoint.
https://github.com/eyereasoner/eyeling
#Notation3 #N3 #SemanticWeb #LinkedData #JavaScript #Reasoning
Gran parte de los datos culturales públicos… no son realmente reutilizables.
Sobre todo no tienen un modelo de conocimiento detrás.
Hace poco trabajé con un dataset de patrimonio cultural de la Región de Murcia.
Decidí convertir esos datos en un grafo de conocimiento interoperable
En el siguiente post explico cómo pasé de XML estático a RDF semántico.
[https://javiermurcia.tech/transformando-el-patrimonio-de-murcia-de-xml-estatico-a-web-semantica-inteligente/]
Demo funcionando [https://javiermurcia.tech/lab/patrimonio-region-murcia/]
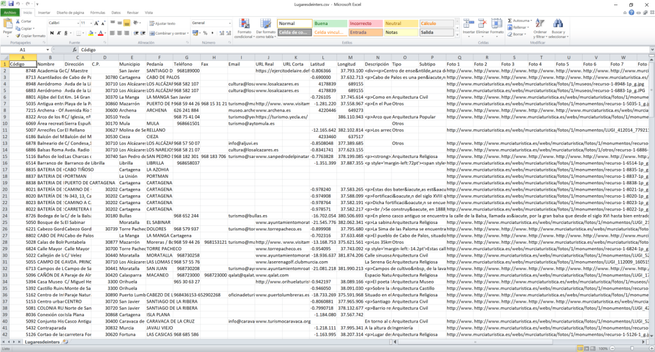
@bencomp Ik vermoed trouwens dat mijn werkgever RAZU nu de enige archiefinstelling in Nederland is die archiveert met metadata in RDF-formaat.
Dat willen we we zo persistent mogelijk doen en daarbij doen we ons best identifiers niet te veranderen, ook niet van door ons toegepaste vocabulaires zoals schema.org.
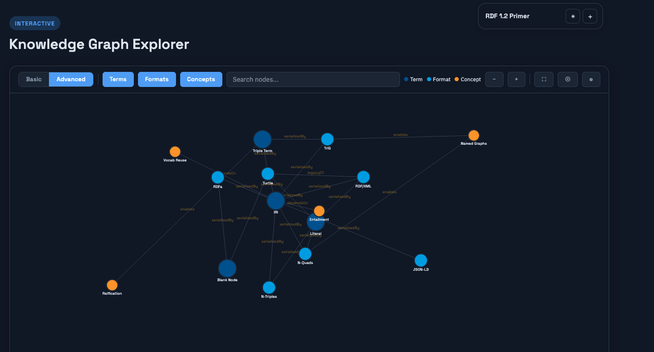
Dogfooding was one of RDF’s biggest challenges prior to the arrival of LLMs as powerful general-purpose clients. Why? Because transforming and presenting RDF specifications in RDF form was difficult. Today, that problem is gone. Here’s an example of the new RDF 1.2 primer, deployed as a knowledge graph that uses Linked Data principles to manifest a Semantic Web.