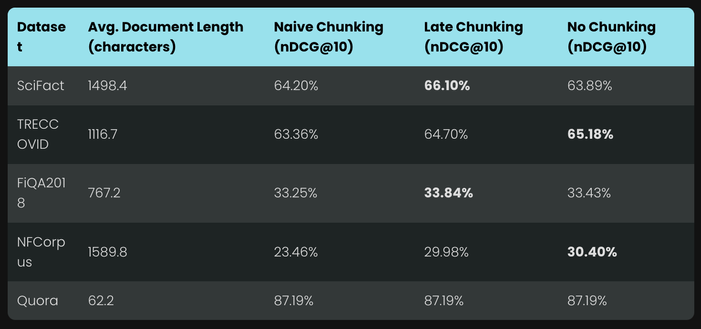
long US weekend — great time to catch up on some #jinaAI papers about rerankers and code / multilingual / multimodal embeddings:
* jina-reranker-v3
* jina-code-embeddings
* jina-embeddings-v4
* ReaderLM-v2
* jina-clip-v2
* jina-reranker-v3
* jina-code-embeddings
* jina-embeddings-v4
* ReaderLM-v2
* jina-clip-v2


 Qiita - 人気の記事
Qiita - 人気の記事